1. ElasticSearch 中的聚合分析
聚合分析,英文Aggregation,是 ES 除了搜索功能之外提供的针对 ES 数据进行统计分析的功能。
- 特点:
- ① 功能丰富,可满足大部分分析需求;
- ② 实时性高,所有计算结果实时返回。
- 基于分析规则的不同,ES 将聚合分析主要划分为以下 4 种:
Metric: 指标分析类型,如:计算最值,平均值等;Bucket: 分桶类型,类似于group by语法,根据一定规则划分为若干个桶分类;Pipeline: 管道分析类型,基于上一级的聚合分析结果进行再分析;Matrix: 矩阵分析类型。
1 | # 聚合分析格式: |
1.1 Metric 聚合分析
主要分为两类:单值分析(输出单个结果)和多值分析(输出多个结果)。
1.1.1 单值分析
min:返回数值类型字段的最小值max:返回数值类型字段的最大值avg:返回数值类型字段的平均值sum:返回数值类型字段值的总和cardinality:返回字段的基数- 使用多个单值分析关键词,返回多个结果
1 | GET my_index/_search |
1.1.2 多值分析
stats:返回所有单值结果extended_stats:对stats进行扩展,包含更多,如:方差,标准差,标准差范围等Percentile:百分位数统计Top hits:一般用于分桶之后获取该桶内最匹配的定不稳当列表,即详情数据
1 | GET my_index/_search |
1.2 Bucket 聚合分析
Bucket,意为桶。即:按照一定规则,将文档分配到不同的桶中,达分类的目的。常见的有以下五类:
Terms: 直接按term进行分桶,如果是text类型,按分词后的结果分桶Range: 按指定数值范围进行分桶Date Range: 按指定日期范围进行分桶Histogram: 直方图,按固定数值间隔策略进行数据分割Date Histogram: 日期直方图,按固定时间间隔进行数据分割
1.2.1 Terms
Terms: 直接按term进行分桶,如果是text类型,按分词后的结果分桶
1 | # 使用terms关键词 |
1.2.2 Range
Range: 按指定数值范围进行分桶:
1 | # 使用range关键词 |
1.2.3 Date Range
Date Range: 按指定日期范围进行分桶
1 | # 使用date_range关键词 |
1.2.4 Histogram
Histogram: 直方图,按固定数值间隔策略进行数据分割
1 | # 使用histogram关键词 |
1.2.5 Date Histogram
Date Histogram: 日期直方图,按固定时间间隔进行数据分割
1 | # 使用date_histogram关键词 |
1.3 Bucket+Metric 聚合分析
Bucket 聚合分析允许通过添加子分析来进一步进行分析,该子分析可以是 Bucket,也可以是 Metric。
- 分桶之后再分桶(Bucket+Bucket),在数据可视化中一般使用千层饼图进行显示。
- 分桶之后再数据分析(Bucket+Metric)
1 | # 分桶之后再分桶——Bucket+Bucket |
1 | # 分桶之后再数据分析——Bucket+Metric |
1.4 Pipeline 聚合分析
针对聚合分析的结果进行再分析,且支持链式调用:
1 | # 使用pipeline聚合分析,计算订单月平均销售额。 |
pipeline的分析结果会输出到原结果中,由输出位置不同,分为两类:Parent和Sibling。
Sibling。结果与现有聚合分析结果同级,如:Max/Min/Sum/Avg Bucket、Stats/Extended Stats Bucket、Percentiles BucketParent。结果内嵌到现有聚合分析结果中,如:Derivate、Moving Average、Cumulative Sum
1 | # Sibling聚合分析(min_bucket) |
1 | # Parent聚合分析(Derivate) |
1.5 聚合分析的作用范围
ES 聚合分析默认作用范围是query的结果集
1 | # ES中聚合分析的默认作用范围是query的结果集 |
可通过以下方式修改:filter、post_filter、global
- filter: 为某个结合分析设定过滤条件,从而在不改变整体 query 语句的情况下修改范围
- post_filter,作用于文档过滤,但在聚合分析之后才生效
- global,无视 query 条件,基于所有文档进行分析
1 | # 使用filter进行过滤 |
1 | # 使用post_filter进行过滤 |
1 | # 使用global进行过滤 |
1.6 聚合分析中的排序
- 可使用自带的关键数据排序,如:
_count文档数、_key按 key 值 - 也可使用聚合结果进行排序
1 | # 使用自带的数据进行排序 |
1 | # 使用聚合结果进行排序 |
1.7 计算精准度问题
ES 聚合的执行流程:每个Shard上分别计算,由coordinating Node做聚合。
Terms计算不准确原因:数据分散在多个Shard上,coordinating Node无法得悉数据全貌,那么在取数据的时候,造成精准度不准确。- 如下图:正确结果应该为
a,b,c,而返回的是 a,b,d
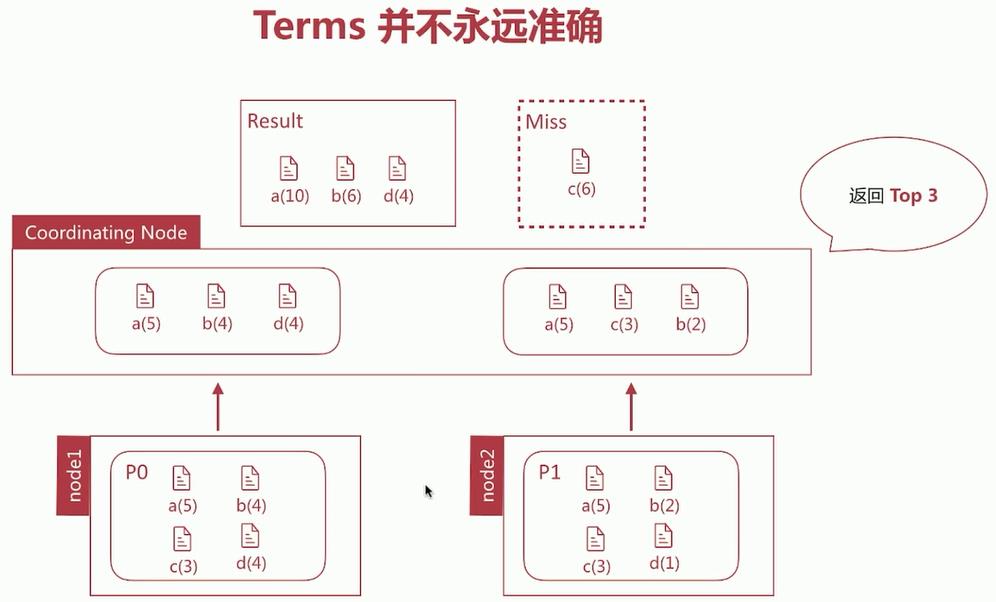
解决办法有两种:
- 直接设置
shard数量为 1;消除数据分散问题,但无法承载大数据量。 - 设置
shard_size大小,即每次从shard上额外多获取数据,从而提升精准度
- 直接设置
terms 聚合返回结果中有两个统计值:
doc_count_error_upper_bound:被遗漏的 term 可能的最大值;sum_other_doc_count:返回结果 bucket 的 term 外其他 term 的文档总数。
设定
show_term_doc_count_error可以查看每个 bucket 误算的最大值(doc_count_error_upper_bound,为0表示计算准确)Shard_Size 默认大小:
(size*1.5)+10- 通过调整 Shard_Size 的大小降低
doc_count_error_upper_bound来提升准确度 - 增大了整体的计算量,从而降低了响应时间
- 通过调整 Shard_Size 的大小降低
权衡
海量数据、精准度、实时性三者只能取其二。Elasticsearch 目前支持两种近似算法:cardinality(度量) 和 percentiles(百分位数度量)
- 结果近似准确,但不一定精准
- 可通过参数的调整使其结果精准,但同时消耗更多时间和性能
2. ElasticSearch 的数据建模
数据建模(Data Modeling)大致分为三个阶段:概念建模、逻辑建模、物理建模
- 概念模型:时间占比
10%- 基础。确定系统的核心需求和范围边界,实际实体与实体之间的关系。
- 逻辑模型:时间占比
60-70%- 核心。确定系统的核心需求和范围边界,实际实体与实体之间的关系。
- 物理模型:时间占比
20-30%- 落地实现。结合具体的数据库产品,在满足业务读写性能等需求的前提下确定最终的定义。
2.1 ES 中的数据建模
ES 是基于 Luence 以倒排索引为基础实现的存储体系,不遵循关系型数据库中的范式约定。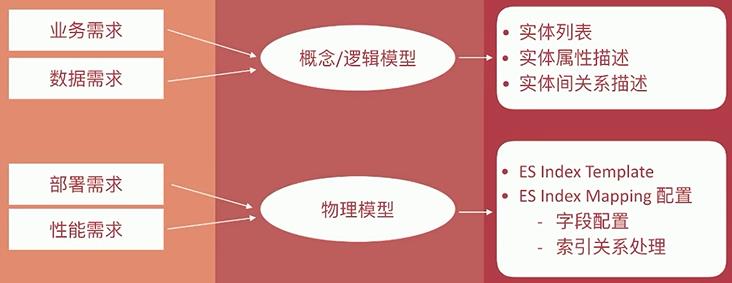
2.2 Mapping 字段相关设置
enabled:true/false。false表示 仅存储,不做搜索或聚合分析。- **
index:true/false。是否构建倒排索引。不需进行字段的检索的时候设为 false。 index_options:docs/freqs/positions/offsets。确定存储倒排索引的哪些信息。norms:true/false。是否存储归一化相关系数,若字段仅用于过滤和聚合分析,则可关闭。doc_values:true/false。是否启用 doc_values,用于排序和聚类分析。默认开启。field_data:true/false。是否设 text 类型为 fielddata,实现排序和聚合分析。默认关闭。store:true/false。是否存储该字段。coerce:true/false。 是否开启数值类型转换功能,如:字符串转数字等。multifields:多字段。灵活使用多字段特性来解决多样业务需求。dynamic:true/false/strict。控制 mapping 自动更新。date_detection:true/false。是否启用自定识别日期类型,一般设为 false,避免不必要的识别字符串中的日期。
2.3 Mapping 字段属性设定流程
判断类型—>是否需要检索—>是否需要排序和聚合分析—>是否需要另行存储
- 判断类型
- 字符串类型:需要分词,则设为 text,否则设为 keyword。
- 枚举类型:基于性能考虑,设为 keyword,即便该数据为整型。
- 数值类型:尽量选择贴近的类型,如 byte 即可表示所有数值时,即用 byte,而不是所有都用 long。
- 其他类型:布尔型,日期类型,地理位置类型等。
- 是否需要检索
- 完全不需要检索、排序、聚合分析的字段
enabled设为false。 - 不需检索的字段
index设为false。 - 需检索的字段,可通过如下配置设定需要的存储粒度:
index_options结合需要设定。norms不需归一化数据时可关闭。
- 完全不需要检索、排序、聚合分析的字段
- 是否需要排序和聚合分析
- 当不需要排序和聚合分析功能时:
doc_values设为false。field_data设为false。
- 当不需要排序和聚合分析功能时:
- 是否需要另行存储
store设为true即可存储该字段的原始内容(且与_source无关),一般结合_source的enabled设为false时使用。
2.4 ES 建模实例
- 针对博客文章设定索引 blog_index,包含字段:
- 标题:title
- 发布日期:publish_data
- 作者:author
- 摘要:abstract
- 网址:url
- 简易的数据模型:
1 | # 简易模型blog_index |
- 如果在
blog_index中加入一个内容字段content
1 | # 为blog_index增加content字段 |
- 在搜索时增加高亮: 在此时,
content里面的数据会存储大量的内容数据,数据量可能达到上千、上万,甚至几十万。那么在搜索的时候,根据search机制,如果还是像之前一样进行_search搜索,并只显示其他字段的话,其实依然还是每次获取了content字段的内容,影响性能,所以,使用stored_fields参数,控制返回的字段。节省了大量资源:
1 | # 使用stored_fields返回指定的存储后的字段 |
注意:
GET blog_index/_search?_source=title虽然只显示了title,但是search机制决定了,会把所有_source内容获取到,但只是显示title。
2.5 ES 中关联关系处理
ES不擅长处理关系型数据库中的关联关系,因为底层使用的倒排索引,如:文章表blog和评论表comment之间通过blog_id关联。
目前 ES 主要有以下 4 种常用的方法来处理关联关系:
Nested Object:嵌套文档Parent/Child:父子文档Data denormalization:数据的非规范化Application-side joins:服务端 Join 或客户端 Join
2.5.1 Application-side joins(服务端 Join 或客户端 Join)
索引之间完全独立(利于对数据进行标准化处理,如便于上述两种增量同步的实现),由应用端的多次查询来实现近似关联关系查询。
- 适用于第一个实体只有少量的文档记录的情况(使用
ES的terms查询具有上限,默认1024,具体可在elasticsearch.yml中修改),并且最好它们很少改变。这将允许应用程序对结果进行缓存,并避免经常运行第一次查询。
2.5.2 Data denormalization(数据的非规范化)
通俗点就是通过字段冗余,以一张大宽表来实现粗粒度的index,这样可以充分发挥扁平化的优势。但是这是以牺牲索引性能及灵活度为代价的。
- 使用的前提:冗余的字段应该是很少改变的;比较适合与一对少量关系的处理。当业务数据库并非采用非规范化设计时,这时要将数据同步到作为二级索引库的 ES 中,就很难使用上述增量同步方案,必须进行定制化开发,基于特定业务进行应用开发来处理
join关联和实体拼接。宽表处理在处理一对多、多对多关系时,会有字段冗余问题,适合“一对少量”且这个“一”更新不频繁的应用场景。
2.5.3 Nested objects(嵌套文档)
索引性能和查询性能二者不可兼得,必须进行取舍。
嵌套文档将实体关系嵌套组合在单文档内部(类似与 json 的一对多层级结构),这种方式牺牲索引性能(文档内任一属性变化都需要重新索引该文档)来换取查询性能,可以同时返回关系实体,比较适合于一对少量的关系处理。
- 当使用嵌套文档时,使用通用的查询方式是无法访问到的,必须使用合适的查询方式(nested query、nested filter、nested facet 等),很多场景下,使用嵌套文档的复杂度在于索引阶段对关联关系的组织拼装。
2.5.4 Parent/Child(父子文档)
父子文档牺牲了一定的查询性能来换取索引性能,适用于一对多的关系处理。其通过两种 type 的文档来表示父子实体,父子文档的索引是独立的。父-子文档 ID 映射存储在 Doc Values 中。当映射完全在内存中时, Doc Values 提供对映射的快速处理能力,另一方面当映射非常大时,可以通过溢出到磁盘提供足够的扩展能力。
在查询 parent-child 替代方案时,发现了一种 filter-terms 的语法,要求某一字段里有关联实体的 ID 列表。基本的原理是在 terms 的时候,对于多项取值,如果在另外的 index 或者 type 里已知主键 id 的情况下,某一字段有这些值,可以直接嵌套查询。具体可参考官方文档的示例:通过用户里的粉丝关系,微博和用户的关系,来查询某个用户的粉丝发表的微博列表。
父子文档相比嵌套文档较灵活,但只适用于“一对大量”且这个“一”不是海量的应用场景,该方式比较耗内存和 CPU,这种方式查询比嵌套方式慢 5~10 倍,且需要使用特定的 has_parent 和 has_child 过滤器查询语法,查询结果不能同时返回父子文档(一次 join 查询只能返回一种类型的文档)。
而受限于父子文档必须在同一分片上,ES 父子文档在滚动索引、多索引场景下对父子关系存储和联合查询支持得不好,而且子文档 type 删除比较麻烦(子文档删除必须提供父文档 ID)。
如果业务端对查询性能要求很高的话,还是建议使用宽表化处理的方式,这样也可以比较好地应对聚合的需求。在索引阶段需要做 join 处理,查询阶段可能需要做去重处理,分页方式可能也得权衡考虑下。
2.6 ES 中的 reindex
reindex:指重建所有数据的过程,一般发生在一下情况:
mapping设置变更,如:字段类型变化,分词器字典更新等;index设置变更,如:分片数变化;- 迁移数据。
- ES 提供了线程的 api 用于完成数据重建:
_update_by_query:在现有索引上重建;_reindex:在其他索引上重建。
1 | # 将blog_index中所有文档重建一遍: |
2.6.1 使用_update_by_query,更新文档的字段值和部分文档:
1 | # 更新文档的字段值及部分文档 |
在 reindex 发起后进入的文档,不会参与重建,类似于快照的机制。因此:一般在文档不再发生变更时,进行文档的 reindex。
2.6.2 使用_reindex,重建数据:
1 | # 使用_reindex: |
- 数据重建时间,受到索引文档规模的影响,此时设定
url参数wait_for_completion为false,来异步执行。 ES通过task来描述此类执行任务,并提供了task api来查看任务的执行进度和相关数据:
1 | # 使用task api |
2.7 其他建议:
- 对 mapping 进行版本管理:
- 要么写文件/注释,加入到
Git仓库,一眼可见; - 要么增加
metadata字段,维护版本,并在每次更新mapping设置的时候加1。
- 要么写文件/注释,加入到
1 | "metadata":{ |
- 防止字段过多:
index.mapping.total_fields_limit,默认1000个。一般是因为没有高质量的数据建模导致,如:dynamic设为true。此时考虑查分多个索引来解决问题。
原文链接: http://chaooo.github.io/2018/11/21/elastic-aggregation.html
版权声明: 转载请注明出处.