Trie 树,也叫“字典树”、“前缀树”。它是一种有序树形结构。是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。AC 自动机以**Trie 树的结构为基础,结合 KMP的思想**建立的,是一种用于解决多模式匹配问题的经典算法。
1. Trie 树 Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。
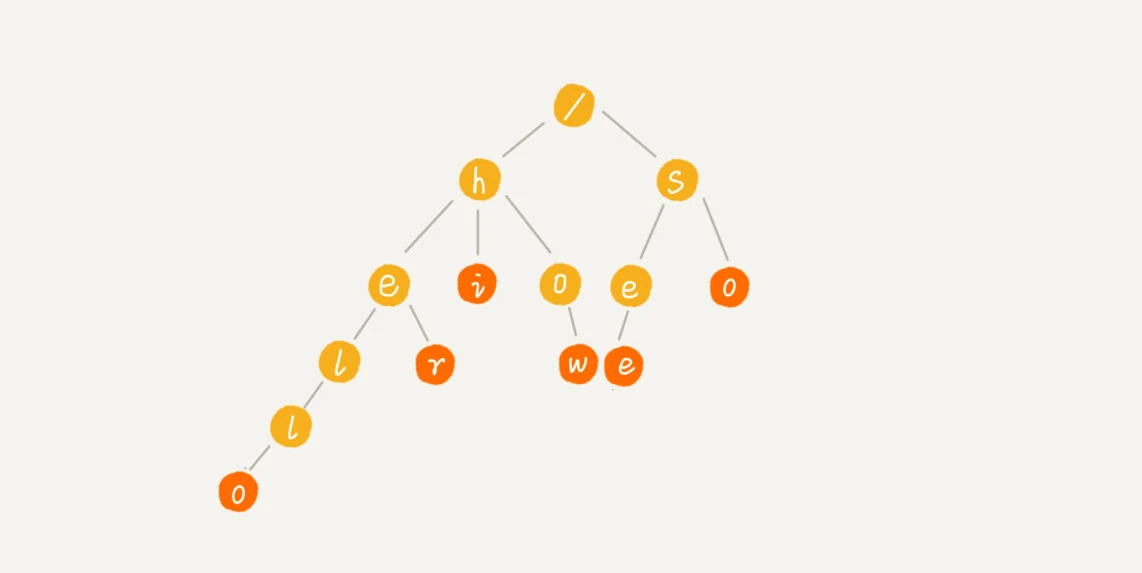
举例说明一下。我们有6个字符串:how,hi,her,hello,so,see。构造出来Trie 树的结构就是下面这个图中的样子。
其中,根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串(注意:红色节点表示一个单词的结尾,红色节点并不都是叶子节点)。
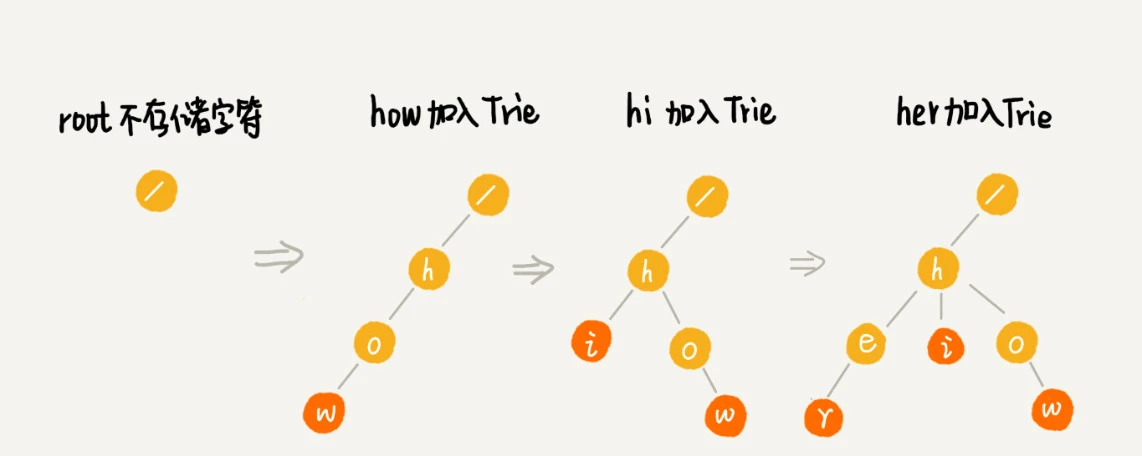
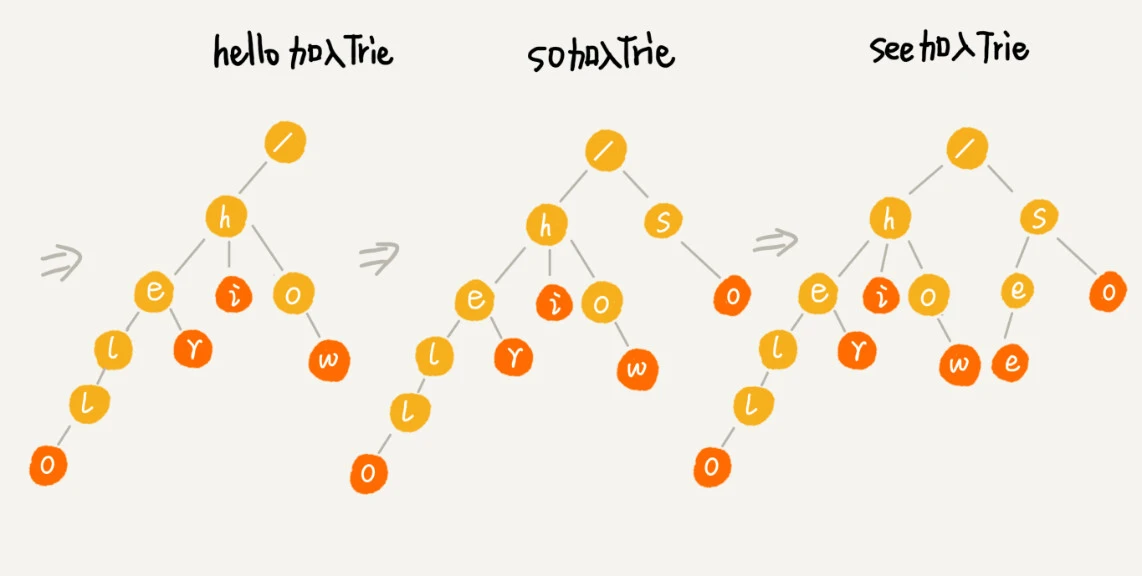
Trie 树构造的分解过程:
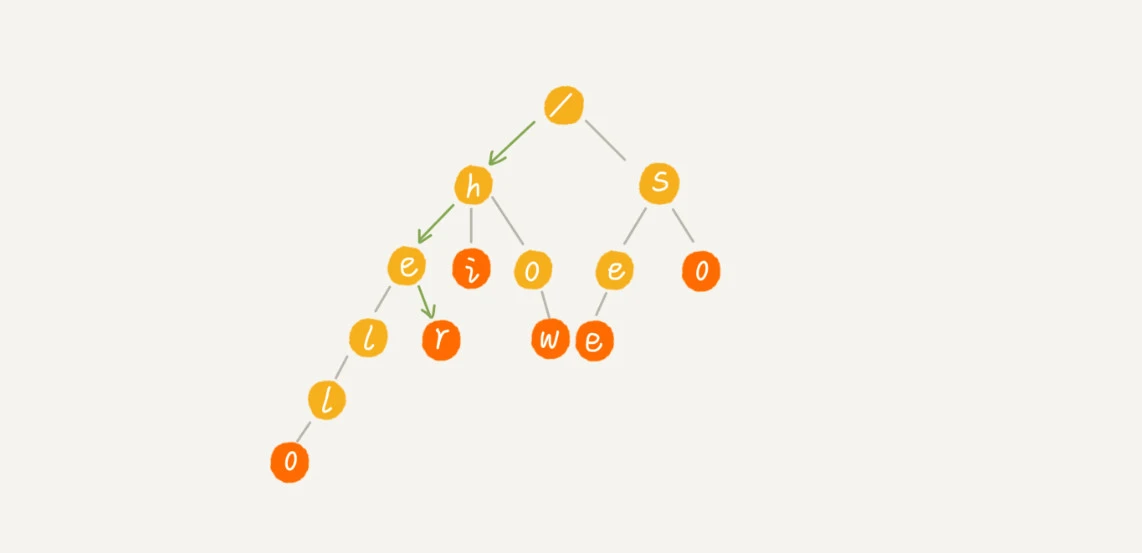
当我们在 Trie 树中查找一个字符串的时候,比如查找字符串“her”,从 Trie 树的根节点开始匹配。如图所示,绿色的路径就是在 Trie 树中匹配的路径。
1.1 Trie 树 的实现 Trie 树是一个多叉树。假如这个字典只包括26个英文字母(暂且都定为小写),那么这个树的深度会由具体单词不一样而定。但是它的广度范围是可以提前确定好的。对于每个节点,广度最大为26。(因为每个节点的下一个字母(即后缀点)只可能是26个字母。)26个元素(a-z)的数组,下标0-25存储子节点数组的位置,子节点数组仍然为26个元素的数组。我们在数组中下标为0的位置,存储指向子节点a的指针,下标为1的位置存储指向子节点b的指针,以此类推,下标为25的位置,存储的是指向的子节点z的指针。如果某个字符的子节点不存在,我们就在对应的下标的位置存储null。
1 2 3 4 class TrieNode { char data; TrieNode children[26 ]; }
当我们在 Trie 树中查找字符串的时候,我们就可以通过字符的ASCII码减去a的ASCII码,迅速找到匹配的子节点的指针。d的ASCII码减去a的ASCII码就是3,那子节点d的指针就存储在数组中下标为3的位置中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Trie { private TrieNode root = new TrieNode ('/' ); public void insert (char [] text) { TrieNode p = root; for (int i = 0 ; i < text.length; ++i) { int index = text[i] - 'a' ; if (p.children[index] == null ) { TrieNode newNode = new TrieNode (text[i]); p.children[index] = newNode; } p = p.children[index]; } p.isEndingChar = true ; } public boolean find (char [] pattern) { TrieNode p = root; for (int i = 0 ; i < pattern.length; ++i) { int index = pattern[i] - 'a' ; if (p.children[index] == null ) { return false ; } p = p.children[index]; } if (p.isEndingChar == false ) return false ; else return true ; } public class TrieNode { public char data; public TrieNode[] children = new TrieNode [26 ]; public boolean isEndingChar = false ; public TrieNode (char data) { this .data = data; } } }
1.2 Trie 树 的复杂度 构建Trie 树的过程,需要扫描所有的字符串,时间复杂度是 O(n)(n 表示所有字符串的长度和)。O(k)(k表示要查找的字符串的长度)。Trie 树的查找时间复杂度O(k)是可以忽略不计的。
Trie 树用的是一种空间换时间的思路,用数组来存储一个节点的子节点的指针。如果字符串中包含从a-z这26个字符,那每个节点都要存储一个长度为26的数组,如果字符串中不仅包含小写字母,还包含大写字母、数字、甚至是中文,那需要的存储空间就更多了。所以,也就是说,在某些情况下,Trie 树不一定会节省存储空间。在重复的前缀并不多的情况下,Trie 树不但不能节省内存,还有可能会浪费更多的内存。Trie 树尽管有可能很浪费内存,但是确实非常高效。那为了解决这个内存问题,我们可以稍微牺牲一点查询的效率,将每个节点中的数组换成其他数据结构,来存储一个节点的子节点指针。比如有序数组、跳表、散列表、红黑树等。
Trie 树可以应用于 搜索引擎的搜索关键词提示、输入法自动补全功能、IDE 代码编辑器自动补全功能、浏览器网址输入的自动补全功能等等。
2. AC 自动机 AC 自动机(Aho-Corasick Automaton)算法,是一种用于解决多模式匹配问题的经典算法。自动机是一个数学模型,自动机的结构就是一张有向图 。通过将模式串预处理为确定有限状态自动机,扫描文本一遍就能结束。其复杂度为O(n),即与模式串的数量和长度无关。AC 自动机以**Trie 树的结构为基础,结合 KMP的思想**建立的。AC 自动机有两个步骤:
基础的Trie 树结构:将所有的模式串构成一棵Trie 树。
KMP 的思想:对Trie 树上所有的结点构造失配指针(相当于KMP中的失效函数next数组)。多模式匹配 了。
单模式串匹配算法,是在一个模式串和一个主串之间进行匹配,也就是说,在一个主串中查找一个模式串。
多模式串匹配算法,就是在多个模式串和一个主串之间做匹配,也就是说,在一个主串中查找多个模式串 。
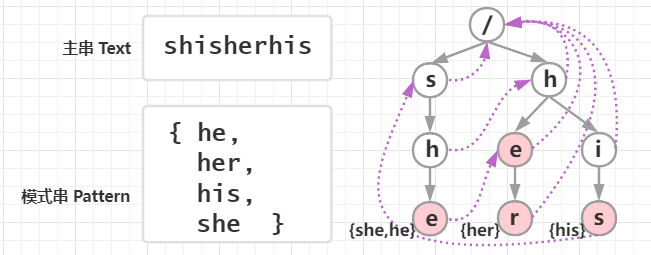
举个AC自动机的构建的例子:假设文本串是shisherhis,模式串有4个,分别为{he,her,his,she},我们用模式串建一颗Trie 树。如下图:
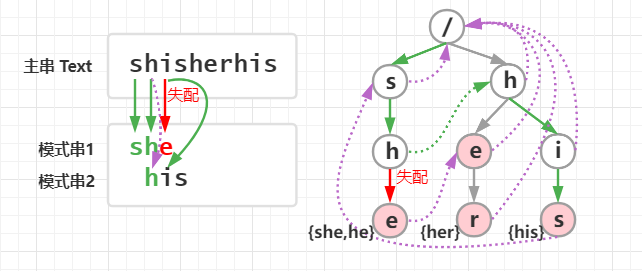
紫色虚线表示失配指针 ,失配指针的作用是在这个模式串失配后快速跳到下一个有可能成功匹配的模式串来匹配,即利用已知信息来加速匹配。如下图:
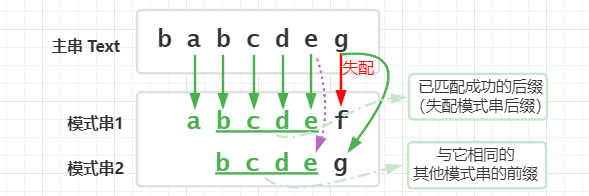
其实,构建失配指针 其实就是在找最长的与当前失配模式串后缀(已匹配后缀)相同的与下一个模式串的前缀 ,其实最长的话就可以保证每个有可能匹配的模式串都匹配到,假设当前节点模式串失配了,就跳最大的前缀,如果又失配,就又到最大前缀的最大前缀,直到没有为止,这样就可以保证全部考虑到。
计算每个节点的失败指针这个过程看起来有些复杂。其实,如果我们把树中相同深度的节点放到同一层,那么某个节点的失败指针只有可能出现在它所在层的上层。KMP 算法那样,当我们要求某个节点的失败指针的时候,我们通过已经求得的、深度更小的那些节点的失败指针来推导。也就是说,我们可以逐层依次来求解每个节点的失败指针。所以,失败指针的构建过程,是一个按层遍历的过程(广度优先搜索(BFS))。
广度优先搜索(Breadth-First-Search),简称 BFS。直观地讲,它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。深度优先搜索(Depth-First-Search),简称 DFS。它会尽可能深地搜索分支,最直观的例子就是“走迷宫”,即走迷宫发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。
3. AC 自动机的 Java 实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 import java.util.*;public class AC { private static final int ASCII = 128 ; private final Node root; private final HashMap<String, List<Integer>> result = new HashMap <>(); private static class Node { public char data; public int depth = 0 ; public Node[] children = new Node [ASCII]; Node fail; public boolean isWord = false ; public Node () {} public Node (char data) { this .data = data; } } private void buildTrieTree (String[] patterns) { for (String pattern : patterns) { result.put(pattern, new LinkedList <Integer>()); Node p = root; for (int i = 0 ; i < pattern.length(); ++i) { char ch = pattern.charAt(i); if (p.children[ch] == null ) { p.children[ch] = new Node (pattern.charAt(i)); p.children[ch].depth = p.depth + 1 ; } p = p.children[ch]; } p.isWord = true ; } } private void buildFailurePointer () { Queue<Node> queue = new LinkedList <>(); for (Node x : root.children){ if (x != null ){ x.fail = root; queue.add(x); } } while (!queue.isEmpty()){ Node p = queue.remove(); for (int i = 0 ; i < p.children.length; i++){ if (p.children[i] != null ){ queue.add(p.children[i]); Node f = p.fail; while (true ){ if (f == null ){ p.children[i].fail = root; break ; } if (f.children[i] != null ){ p.children[i].fail = f.children[i]; break ; } else { f = f.fail; } } } } } } public AC (String[] patterns) { root = new Node (); buildTrieTree(patterns); buildFailurePointer(); } public HashMap<String, List<Integer>> match (String text) { Node p = root; int i = 0 ; while (i < text.length()){ char ch = text.charAt(i); if (p.children[ch] != null ){ p = p.children[ch]; if (p.isWord){ String pattern = text.substring(i - p.depth + 1 , i + 1 ); result.get(pattern).add(i - p.depth + 1 ); } if (p.fail != null && p.fail.isWord){ String pattern = text.substring(i - p.fail.depth + 1 , i + 1 ); result.get(pattern).add(i - p.fail.depth + 1 ); } i++; } else { p = p.fail; if (p == null ){ p = root; i++; } } } return result; } }
AC自动机 测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Test void testAC () { String[] patterns = {"he" ,"her" ,"his" ,"she" }; String text = "shisherhis" ; AC ac = new AC (patterns); HashMap<String, List<Integer>> result = ac.match(text); System.out.println("文本串“" + text + "”的匹配结果:" ); for (Map.Entry<String, List<Integer>> entry : result.entrySet()){ System.out.println(entry.getKey()+" : " + entry.getValue()); } }
输出结果:
1 2 3 4 5 文本串“shisherhis”的匹配结果: she : [3] his : [1, 7] her : [4] he : [4]
原文链接: http://chaooo.github.io/2022/07/06/data-structure-trie-ac.html
版权声明: 转载请注明出处.