1. ElasticSearch 的分布式特性
1.1 分布式介绍
ES支持集群模式,即一个分布式系统。其好处主要有以下 2 个:- 可增大系统容量。比如:内存、磁盘的增加使得
ES能够支持PB级别的数据; - 提高了系统可用性。即使一部分节点停止服务,集群依然可以正常对外服务。
- 可增大系统容量。比如:内存、磁盘的增加使得
ES集群由多个ES实例构成。 + 不同集群通过集群名字来区分,通过配置文件elasticsearch.yml中的cluster.name可以修改,默认为elasticsearch+ 每个ES实例的本质,其实是一个JVM进程,且有自己的名字,通过配置文件中的node.name可以修改。
1.2 构建 ES 集群
1 | # 创建一个本地化集群my_cluster |
可以通过 cerebro 插件可以看到,集群
my_cluster中存在三个节点,分别为:node1、node2、node3
- **
Cluster State**:ES 集群相关的数据,主要记录如下信息:- 节点信息:如节点名称、连接地址等
- 索引信息:如索引名称、配置等
Master Node:主节点,可修改cluster state的节点。一个集群只能有一个。cluster state存储于每个节点上,master维护最新版本并向其他从节点同步。- master 节点是通过集群中所有节点选举产生的,可被选举的节点称为**
master-eligible节点** - 通过配置
node.master:true设置节点为可被选举节点(默认为 true)
- **
Cordinating Node**:处理请求的节点。是所有节点的默认角色,且不能取消。- 路由请求到正确的节点处理,如:创建索引的请求到 master 节点。
- **
Data Node**:存储数据的节点,默认节点都是data类型。配置node.data:true。
1.3 副本与分片
提高系统可用性:
- 服务可用性:集群
- 数据可用性:副本(Replication)
增大系统容量:分片(Shard)
分片是
ES能支持PB级别数据的基石:可在创建索引时指定- 分片存储部分数据,可以分布于任意节点;
- 分片数在索引创建时指定,且后续不能更改,默认为 5 个;
- 有主分片和副本分片之分,以实现数据的高可用;
- 副本分片由主分片同步数据,可以有多个,从而提高数据吞吐量。
分片数的设定很重要,需要提前规划好
- 过小会导致后续无法通过增加节点实现水平扩容
- 过大会导致一个节点分片过多,造成资源浪费,同时会影响查询性能
例如:在 3 个节点的集群中配置索引指定 3 个分片和 1 个副本(
index.number_of_shards:3,index.number_of_replicas:1),分布如下:
怎样增加节点或副本提高索引的吞吐量
- 同时增加新的节点和加新的副本,这样把新的副本放在新的节点上,进行索引数据读取的时候,并且读取,就会提升索引数据读取的吞吐量。
1.4 ES 集群状态 与 故障转移
- ES 的**健康状态(
Cluster Health)**分为三种:Greed,绿色。表示所有主分片和副本分片都正常分配;Yellow,黄色。表示所有主分片都正常分配,但有副本分片未分配;Red,红色。表示有主分片未分配。
- 可通过
GET _cluster/health查看集群状态- 返回集群名称,集群状态,节点数,活跃分片数等信息。
- 如果此时磁盘空间不够,name 在创建新的索引的时候,主副分片都不会再分配,此时的集群状态会直接飙红,但此时依然可以访问集群和索引,也可以正常进行搜索。
- 所以:ES 的集群状态为红色,不一定就不能正常服务。
- 故障转移
Failover- 当其余节点发现定时 ping 主节点 master 无响应的时候,集群状态转为 Red。此时会发起 master 选举。
- 新 master 节点发现若有主分片未分配,会将副本分片提升为主分片,此时集群状态转为 Yellow。
- 新 master 节点会将提升后的主分片生成新的副本,此时集群状态转为 Green。整个故障转移过程结束。
1.5 文档分布式存储
通过文档到分片的映射算法,使文档均匀分布到所有分片上,以充分利用资源。
文档对应分片计算公式:
shard = hash(routing)%number_of_primary_shardshash保证数据均匀分布在分片中routing作为关键参数,默认为文档 ID,也可自行指定number_of_primary_shards为主分片数
主分片数一旦设定,不能更改:
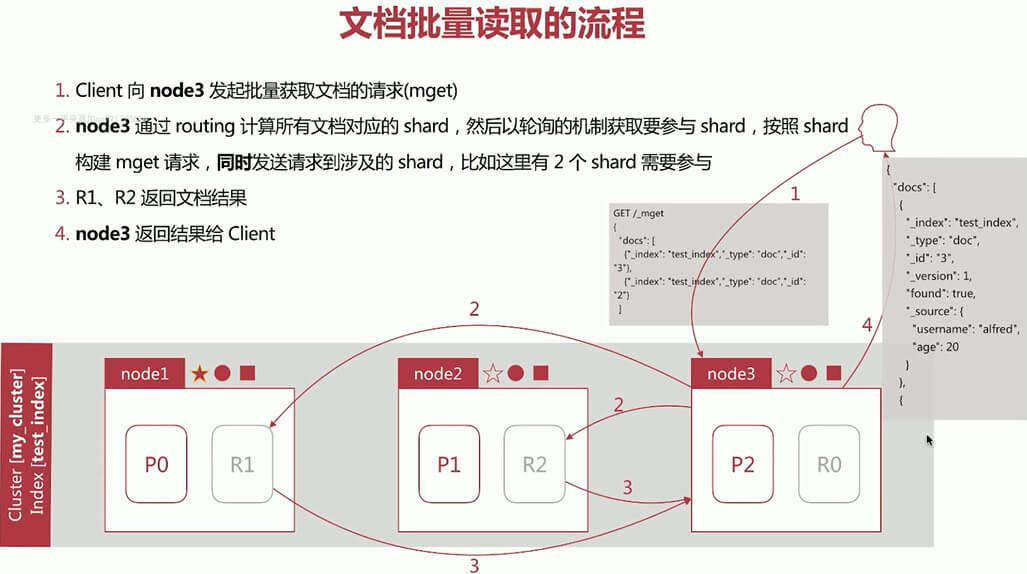
为了保证文档对应的分片不会发生改变。文档创建流程:
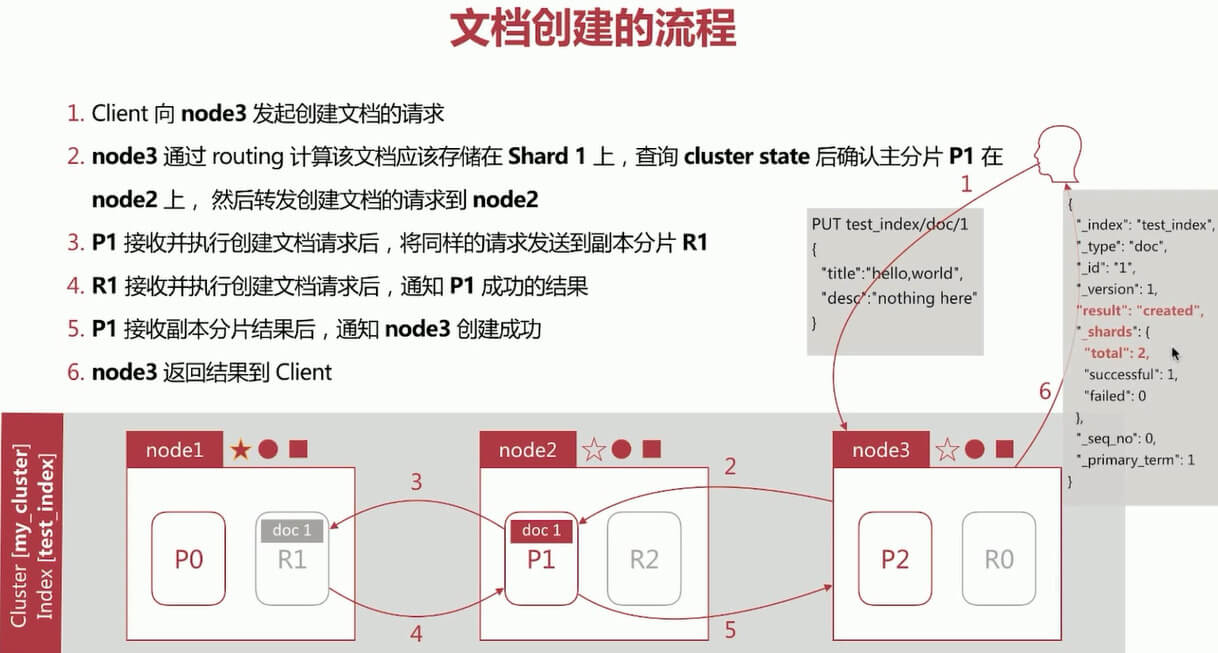
文档读取流程
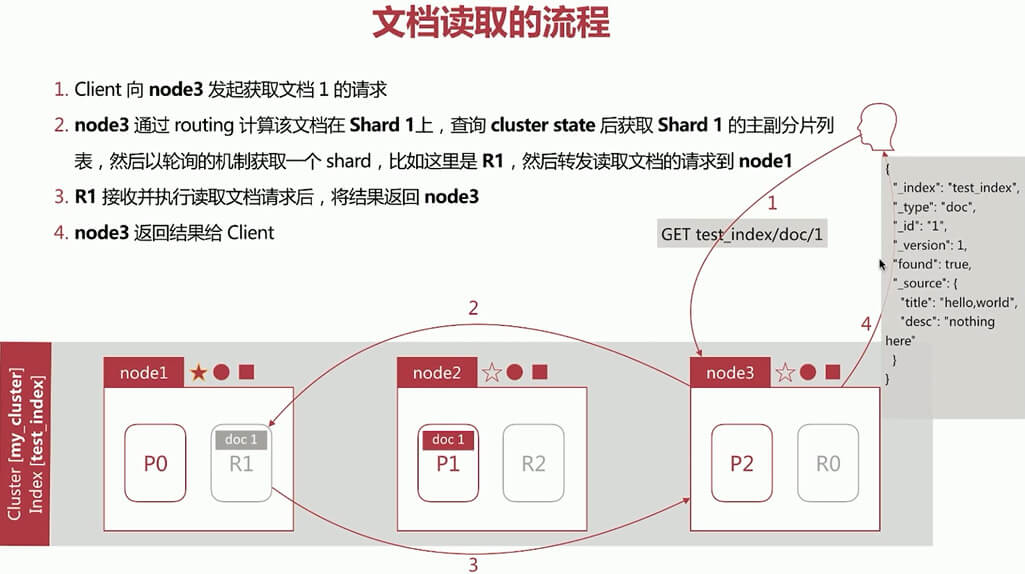
文档批量创建流程
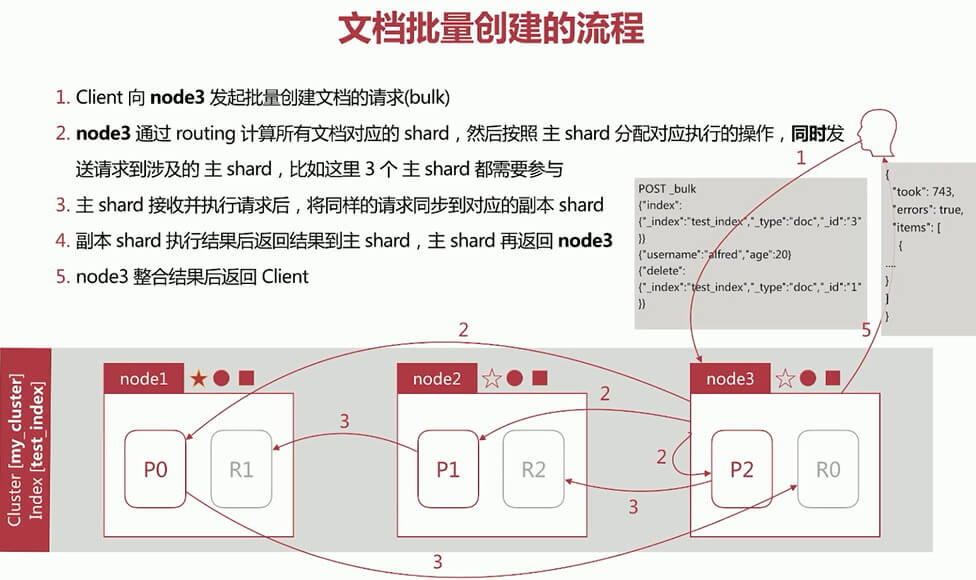
文档批量读取流程
1.6 脑裂问题
- 在分布式系统中一个经典的网络问题
- 当一个集群在运行时,作为
master节点的node1的网络突然出现问题,无法和其他节点通信,出现网络隔离情况。那么node1自己会组成一个单节点集群,并更新cluster state;同时作为data节点的node2和node3因为无法和node1通信,则通过选举产生了一个新的master节点node2,也更新了cluster state。那么当node1的网络通信恢复之后,集群无法选择正确的master。
- 当一个集群在运行时,作为
- 解决方案也很简单:
- 仅在可选举的
master-eligible节点数>=quorum的时候才进行master选举。 quorum(至少为2)=master-eligible数量/2 + 1。- 通过
discovery.zen.minimum_master_nodes为quorum即可避免脑裂。
- 仅在可选举的
1.7 Shards 分片详解
- 倒排索引一旦生成,不能更改。
- 优点:
- 不用考虑并发写文件的问题,杜绝了锁机制带来的性能问题
- 文件不在更改,则可以利用文件系统缓存,只需载入一次,只要内存足够,直接从内存中读取该文件,性能高;
- 利于生成缓存数据(且不需更改);
- 利于对文件进行压缩存储,节省磁盘和内存存储空间。
- 缺点:在写入新的文档时,必须重构倒排索引文件,然后替换掉老倒排索引文件后,新文档才能被检索到,导致实时性差。
- 优点:
- 解决文档搜索的实时性问题的方案:
- 新文档直接生成新待排索引文件,查询时同时查询所有倒排索引文件,然后做结果的汇总即可,从而提升了实时性。
SegmentLucene就采用了上述方案,构建的单个倒排索引称为Segment,多个Segment合在一起称为Index(Lucene中的Index)。在ES中的一个shard分片,对应一个Lucene中的Index。且Lucene有一个专门记录所有Segment信息的文件叫做Commit Point。Segment写入磁盘的过程依然很耗时,可以借助文件系统缓存的特性。「先将Segment在内存中创建并开放查询,来进一步提升实时性」,这个过程在ES中被称为:refresh。- 在
refresh之前,文档会先存储到一个缓冲队列buffer中,refresh发生时,将buffer中的所有文档清空,并生成Segment。 ES默认每1s执行一次refresh操作,因此实时性提升到了1s。这也是ES被称为近实时的原因(Near Real Time)。
translog文件translog机制:当文档写入buffer时,同时会将该操作写入到translog中,这个文件会即时将数据写入磁盘,在 6.0 版本之后默认每个要求都必须落盘,这个操作叫做fsync操作。这个时间也是可以通过配置:index.translog.*进行修改的。比如每五秒进行一次fdync操作,那么风险就是丢失这5s内的数据。
- 文档搜索实时性——
flush(十分重要)flush的功能,就是:将内存中的Segment写入磁盘,主要做如下工作:- 将
translog写入磁盘; - 将
index bufffer清空,其中的文档生成一个新的Segment,相当于触发一次refresh; - 更新
Commit Point文件并写入磁盘; - 执行
fsync落盘操作,将内存中的Segment写入磁盘; - 删除旧的
translog文件。
- 将
refresh与flush的发生时机refresh:发生时机主要有以下几种情况:- 间隔时间达到。
- 通过
index.settings.refresh_interval设置,默认为1s。
- 通过
index.buffer占满时。- 通过
indices.memory.index_buffer_size设置,默认JVM heap的10%,且所有shard共享。
- 通过
flush发生时。会触发一次refresh。
- 间隔时间达到。
flush:发生时机主要有以下几种情况:- 间隔时间达到。
- 5.x 版本之前,通过
index.translog.flush_threshold_period设置,默认 30min。 - 5.x 版本之后,ES 强制每 30min 执行一次 flush,不能再进行更改。
- 5.x 版本之前,通过
translog占满时。- 通过
index.translog.flush_threshold_size设置,默认512m。且每个Index有自己的translog。
- 通过
- 间隔时间达到。
- 删除和更新文档:
- 删除:
Segment一旦生成,就不能更改,删除的时候,Lucene专门维护一个.del文件,记录所有已删除的文档。.del文件上记录的是文档在Lucene中的ID,在查询结果返回之前,会过滤掉.del文件中的所有文档。
- 更新:
- 先删除老文档,再创建新文档,两个文档的
ID在Lucene中的ID不同,但是在ElasticSearch中ID相同。
- 先删除老文档,再创建新文档,两个文档的
- 删除:
Segment Merging(合并)- 随着
Segment的增多,由于每次查询的Segment数量也增多,导致查询速度变慢; ES会定时在后台进行Segment merge的操作,减少Segment数量;- 通过
force_merge api可以手动强制做Segment的合并操作。
- 随着
2. ElasticSearch 的集群优化
2.1 生产环境部署
- 遵照官方建议设置所有系统参数。
- 在 ES 的配置文件中 elasticsearch.yml 中,尽量只写必备的参数,其他可通过 api 进行动态设置,随着 ES 版本的不断升级,很多网上流传的参数,现在已经不再适用,所以不要胡乱复制。
- 建议设置的基本参数有:
cluster.namenode.namenode.master/node.data/node.ingestnetwork.host: 建议显示指定为服务器的内网ip,切勿直接指定0.0.0.0,很容易直接从外部被修改ES数据。discovery.zen.ping.unicast.hosts: 设置集群其他节点地址,一般设置选举节点即可discovery.zen.minimum_master_nodes: 一般设置为2,有3个即可。path.data/path.log- 除上述参数外,再根据需要增加其他的静态配置参数,如:
refresh优化参数,indices.memory.index_buffer_size。
- 动态设定的参数有 transient(短暂的)和 persistent(持续的)两种,前者在集群重启后会丢失,后者在集群重启后依然# 生效。二者都覆盖了 yml 中的配置,举例:
1 | # 使用transient和persistent动态设置ES集群参数 |
- 关于 JVM 内存设定
- 每个节点尽量不要超多
31GB。 - 预留一半内存给操作系统,用来做文件缓存。ES 的具体内存大小根据 node 要存储的数据量来估算,为了保证性能
- 搜索类项目中:内存:数据量 ===> 1:16;
- 日志类项目中:内存:数据量 ===> 1:48/96。
- 每个节点尽量不要超多
1 | 假设现有数据1TB,3个node,1个副本,那么: |
2.2 写性能优化
在写上面的优化,主要是增大写的吞吐量——EPS(Event Per Second)
- 优化方案:
Client:多线程写,批量写bulk;ES:在高质量数据建模的前提下,主要在refresh、translig和flush之间做文章。
- 降低
refresh写入内存的频率:- 增大
refresh_interval,降低实时性,增大每次refresh处理的文件数,默认 1s。可以设为-1s,禁止自动refresh。 - 增大
indexbuffer大小,参数为:indices.memory.index_buffer_size。此为静态参数,需设定在elasticsea.yml中,默认10%
- 增大
- 降低 translog 写入磁盘频率,同时会降低容灾能力:
index.translog.durability:设为async;index.translog.sync_interval。设置需要的大小如:120s => 每 120s 才写一次磁盘。index.translog.flush_threshold_size。默认 512m。即当translog大小超过此值,会触发一次flush,可以调大避免flush过早触发。
- 在
flush方面,从 6.x 开始,ES 固定每 30min 执行一次,所以优化点不多,一般都是 ES 自动完成。 - 其他:
- 将副本数设置为 0,在文档全部写完之后再加副本;
- 合理设计
shard数,保证shard均匀地分布在所有node上,充分利用node资源:index.routing.allocation.total_shards_per_node:限定每个索引在每个node上可分配的主副分片数,- 如:有
5个node,某索引有10个主分片,1个副本(10个副分片),则:20/5=45,但是实际要设置为5,预防某个node下线后分片迁移失败。
写性能优化,主要还是 index 级别的设置优化。
一般在 refresh、translog、flush 三个方面进行优化;
2.3 读性能优化
- 主要受以下几方面影响:
- 数据模型是否符合业务模型?
- 数据规模是否过大?
- 索引配置是否优化?
- 查询运距是否优化?
- 高质量的数据建模
- 将需通过
cripte脚本动态计算的值,提前计算好作为字段存入文档中; - 尽量使数据模型贴近业务模型
- 将需通过
- 根据不同数据规模设定不同的
SLA(服务等级协议),万级数据和千万级数据和亿万级数据性能上肯定有差异; - 索引配置优化
- 根据数据规模设置合理的分片数,可通过测试得到最适合的分片数;
- 分片数并不是越多越好
- 查询语句优化
- 尽量使用
Filter上下文,减少算分场景(Filter有缓存机制,能极大地提升查询性能); - 尽量不用
cript进行字段计算或算分排序等; - 结合
profile、explain API分析慢查询语句的症结所在,再去优化数据模型。
- 尽量使用
2.4 其他优化点
- 如何设定
shard数?ES的性能基本是线性扩展的,因此,只需测出一个shard的性能指标,然后根据实际的性能需求就可算出所需的shard数。- 测试一个
shard的流程如下:- 搭建与生产环境相同配置的单节点集群;
- 设定一个单分片
0副本的索引; - 写入实际生产数据进行测试,获取(写性能指标);
- 针对数据进行查询操作,获取(读性能指标)。
- 压力测试工具,可以采用
ES自带的esrally,从经验上讲:- 如果是搜索引擎场景,单
shard大小不超过15GB; - 如果是日志分析场景,单
shard大小不超过50GB; - 估算索引的总数据大小,除以上述单
shard大小,也可得到经验上的分片数。
- 如果是搜索引擎场景,单
2.5 ES 集群监控
使用官方免费插件X-pack。
- 安装与启动:
1 | # X-pack的安装 |
之后重启ES集群即可。
在kibana的界面可以看到新增了工具,使用Monitoring进行集群监控。
3. ElasticSearch 中 Search 的运行机制
Search执行的时候,实际分为两个步骤执行:Query阶段:搜索Fetch阶段:获取
3.1 Query—Then—Fetch:
若集群my_cluster中存在三个节点 node1、node2、node3,其中master为 node1,其余的为data节点。
Query阶段: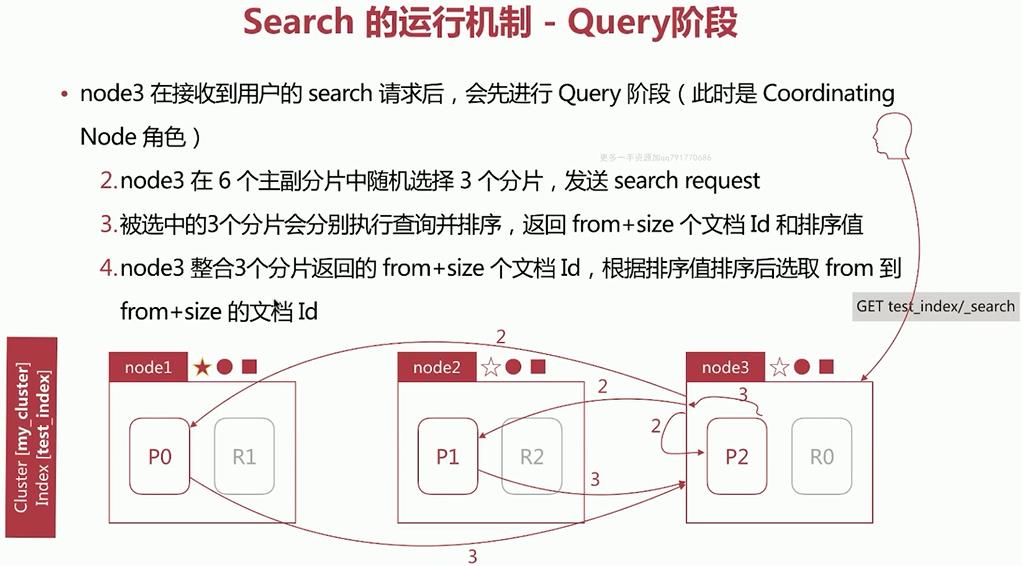
Fetch阶段: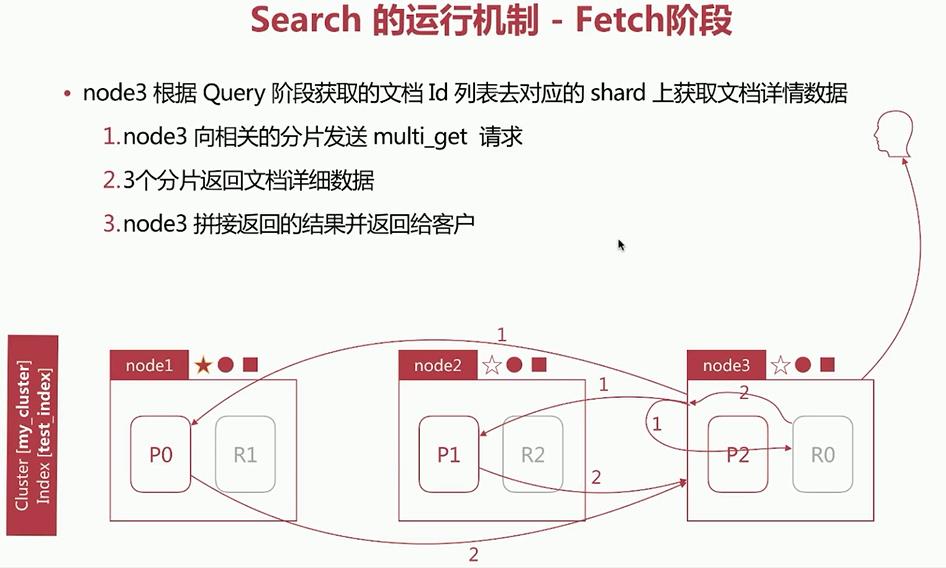
3.2 相关性算分:
相关性算分在shard和shard之间是相互独立的。也就意味着:同一个单词term在不同的shard上的TDF等值也可能是不同的。得分与shard有关。
当文档数量不多时,会导致相关性算分严重不准的情况发生。
- 解决方案:
- 设置分片数为
1个,从根本上排除问题。(此方案只适用于百万/少千万级的少量数据) - 使用
DFS Query-then-Fetch查询方式。
- 设置分片数为
DFS Query-then-Fecth:- 在拿到所有文档后,再重新进行完整的计算一次相关性得分,耗费更多的 CPU 和内存,执行性能也较低。所以也不推荐。
1 | # 使用DLS Query-then-Fetch进行查询: |
3.3 排序相关:
默认采用相关性算分结果进行排序。可通过sort参数自定义排序规则,如:
1 | # 使用sort关键词进行排序 |
- 直接按数字/日期排序,如上例中
birth - 按字符串进行排序:字符串排序较特殊,因为在
ES中有keyword和text两种:
1 | # 直接对text类型进行排序 |
3.3.1 关于 fielddata 和 docvalues:
排序的实质是对字段的原始内容排序的过程,此过程中倒排索引无法发挥作用,需要用到正排索引。即:通过文档ID和字段得到原始内容。
- ES 提供 2 中实现方式:
Fielddata。 默认禁用。DocValues。 默认启用,除了 text 类型。
| 对比 | Fielddata | DocValues |
|---|---|---|
| 创建时机 | 搜索时即时创建 | 创建索引时创建,和倒排索引创建时间一致 |
| 创建位置 | JVM Heap | 磁盘 |
| 优点 | 不占用额外磁盘空间 | 不占用 Heap 内存 |
| 缺点 | 文档较多时,同时创建会花费过多时间,占用过多 Heap 内存 | 减慢索引的速度,占用额外的磁盘空间 |
3.3.2 Fielddata 的开启:
Fielddata默认关闭,可通过如下 api 进行开启,且在后续使用时随时可以开启/关闭:
- 使用场景:一般在对分词做聚合分析的时候开启。
1 | # 开启字段的fielddata设置 |
3.3.3 Docvalues 的关闭
Docvalues默认开启,可在创建索引时关闭,且之后不能再打开,要打开只能做 reindex 操作。
- 使用场景:当明确知道,不会使用这个字段排序或者不做聚合分析的时候,可关闭 doc_values,减少磁盘空间的占用。
1 | # 关闭字段的docvalues设置 |
3.4 分页与遍历
ES 提供了三种方式来解决分页和遍历的问题: from/size,scroll,search_after。
3.4.1 from/size
from:指明开始位置;size:指明获取总数
1 | # 使用from——size |
- 经典问题:深度分页。
- 问题:如何在数据分片存储的情况下, 获取前 1000 个文档?
- 答案:
- 先从每个分片上获取前 1000 个文档, 然后由处理节点聚合所有分片的结果之后,再排序获取前 1000 个文档。
- 此时页数越深,处理的文档就越多,占用的内存就越大,耗时就越长。这就是深度分页问题。
- 为了尽量避免深度分页为题,ES 通过设定
index.max_result_window限定最多到 10000 条数据。
- 在设计分页系统时,有一个分页数十分重要:
total_page=(total + page_size -1) / page_size- 总分页数= (文档总数+认为设定的文档大小-1) / 人为设定的文档大小
- 但是在搜索引擎中的意义并不大,因为如果排在前面的结果都不能让用户满意,那么越往后,越不能让用户满意。
3.4.2 scroll
- 遍历文档集的
API,以快照的方式来避免深度分页问题。- 不能用来做实时搜索,因为数据不是实时的;
- 尽量不用复杂的
sort条件,使用_doc最高效; - 使用比较复杂。
- 步骤:
- 发起一个
scroll search,会返回后续会用到的_scroll_id - 调用
scroll search的api,获取文档集合,不断迭代至返回hits数组为空时停止 - 之后不断返回新的
_scroll_id,使用新的_scroll_id进行查询,直到返回数组为空。 - 当不断的进行迭代,会产生很多
scroll,导致大量内存被占用,可以通过clear api进行删除
- 发起一个
1 | # 发起一个scroll search |
3.4.3 search_after
避免深度分页的性能问题,提供实时的下一页文档获取功能。
- 缺点:不能使用 from 参数,即:不能指定页数。且只能下一页,不能上一页。
- 使用步骤:
- 第一步:正常搜索,但是要指定 sort 值,并保证值唯一:
- 第二步:使用上一步最后一个文档的 sort 值进行查询:
1 | # 第一步,正常搜索 |
3.4.4 如何避免深度分页问题:
这个问题目前连 google 都没能解决,所以只能最大程度避免,通过唯一排序值定位每次要处理的文档数都控制在 size 内:
- 应用场景:
- from/size:需实时获取顶部的部分文档,且需自由翻页(实时);
- scroll:需全部文档,如:导出所有数据的功能(非实时);
- search_after:需全部文档,不需自由翻页(实时)。
原文链接: http://chaooo.github.io/2018/11/17/elastic-search.html
版权声明: 转载请注明出处.