数据结构可以看作是算法实现的容器,通过一系列特殊结构的数据集合,能够将算法更为高效而可靠的执行起来。
算法(Algorithm)是为了解决一个特定的问题而精心设计的一套数学模型以及在这套数学模型上的一系列操作步骤,这些操作步骤是将描述的输入数据逐步处理、转换,并最后得到一个确定的结果。
一般来说,算法设计没有什么固定的方法可循。但是通过大量的实践,也总结出算法某些共性的规律,包括枚举(Enumeration)、递归(Recursion)、分支法(Divide and Conquer)、贪心法(Greedy)、回溯法(Backtracking)、动态规划法(Dynamic Programming)等。
1. 枚举
枚举(Enumeration)又称暴力枚举,顾名思义,就是穷尽列举。基本思想是:按问题本身的性质,一一列举出该问题所有可能的解,并在逐一列举的过程中,检验每个可能的解是否真正的解,若是,就采纳,否则就放弃。
- 枚举思想的本质就是从所有候选答案中去搜索正确的解,使用枚举需要满足两个条件:
- 可预先确定候选答案的数量;
- 候选答案的范围在求解之前必须有一个确定的集合。
枚举简单粗暴,因为暴力的枚举所有可能,尽可能地尝试所有的方法;因此比较直观,易于理解,得到的结果总是正确的。
枚举的效率取决于枚举状态的数量以及单个状态枚举的代价,因此效率比较低。
2. 递归
程序调用自身的编程技巧称为递归(Recursion)。递归思想往往用函数的形式来体现,所以需要预先编写功能函数。这些函数是独立的功能,能够实现解决某个问题的具体功能,当需要时直接调用这个函数即可。
「递归」,先有「递」再有「归」。
「递」的意思是将问题拆解成子问题来解决,子问题再拆解成子子问题,…,直到无法被拆解(找到终止条件,即可以求解);
「归」是说最小的子问题解决了,那么它的上一层子问题也就解决了,上一层的子问题解决了,上上层子问题自然也就解决了。
- 实际上,递归有两个显著的特征:自身调用和终止条件;
- 自身调用:原问题可以分解为子问题,子问题和原问题的求解方法是一致的,即都是调用自身的同一个函数。
- 终止条件:递归必须有一个终止的条件,即不能无限循环地调用本身。
编写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
- 例如递归实现 斐波那契数列数列(1、1、2、3、5、8、13、21、34、…)
- 递推公式:
f(n)=f(n-1)+f(n-2); - 终止条件:当n=1或者n=2时,
f(1)=f(2)=1。
- 递推公式:
1 | int fibonacci(int n){ |
- 递归代码虽然表达力很强,写起来非常简洁,但是,递归代码也有很多弊端。比如,堆栈溢出、重复计算、函数调用耗时多、空间复杂度高等。
- 堆栈溢出:函数调用会使用栈来保存临时变量。每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时,才出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险。
- 重复计算:比如想要计算
f(5),需要先计算f(4)和f(3),而计算f(4)还需要计算f(3),因此f(3)就被重复计算了多次。为了避免重复计算,可以通过一个数据结构(比如散列表)来保存已经求解过的 f(k)。当递归调用到 f(k) 时,先看下是否已经求解过了。 - 函数调用耗时多:递归代码里多了很多函数调用,当这些函数调用的数量较大时,就会积聚成一个可观的时间成本。
- 空间复杂度高:因为递归调用一次就会在内存栈中保存一次现场数据,所以在分析递归代码空间复杂度时,需要额外考虑这部分的开销。
所以,在开发过程中,我们要根据实际情况来选择是否需要用递归的方式来实现。
3. 分治算法
分治算法(Divide and Conquer)的核心思想其实就是四个字,分而治之 ,也就是将原问题划分成 n 个规模较小,并且结构与原问题相似的子问题,递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
分治算法是一种处理问题的思想,递归是一种编程技巧。实际上,分治算法一般都比较适合用递归来实现。
- 分治算法的递归实现中,每一层递归都会涉及这样三个操作:
- 分解:将原问题分解成一系列子问题;
- 解决:递归地求解各个子问题,若子问题足够小,则直接求解;
- 合并:将子问题的结果合并成原问题。
- 分治算法的典型的应用场景:
- 用来指导编码,降低问题求解的时间复杂度。
- 应用在海量数据处理的场景中。
比如 大规模计算框架MapReduce 本质上就是利用了分治思想。实际上,MapReduce 框架只是一个任务调度器,底层依赖 GFS 来存储数据,依赖 Borg 管理机器。它从 GFS 中拿数据,交给 Borg 中的机器执行,并且时刻监控机器执行的进度,一旦出现机器宕机、进度卡壳等,就重新从 Borg 中调度一台机器执行。
4. 贪心算法
贪心算法(Greedy)是指,在对问题求解时,总是做出在当前看来是最好的选择(只顾眼前)。也就是说,不从整体最优上加以考虑,得到的是在某种意义上的局部最优解。
贪心策略适用的前提是:局部最优策略能导致产生全局最优解。即问题能够分解成子问题,子问题最优解能够递推到整体最优解。所以选择的贪心策略必须具备无后效性(即某个状态以后的过程不会影响以前的状态,只与当前状态有关)。
贪心策略一旦经过证明成立后,它就是一种高效的算法。比如霍夫曼编码(Huffman Coding)、Prim 和 Kruskal 最小生成树算法、还有 Dijkstra 单源最短路径算法。
4.1 贪心算法实现霍夫曼编码
通常的编码方式有固定长度编码和不定长度编码两种。哈夫曼编码就是不定长度的编码,它利用字符的使用频率来编码,经常使用的字符编码较短,不常使用的字符编码较长。目的是为了总的编码长度最短,空间效率最高,它是由数学家Huffman在1952年提出的。霍夫曼编码广泛用于数据压缩中,其压缩率通常在 20%~90% 之间。
- 不定长编码需要解决两个关键问题:
- 编码尽可能短:让使用频率高的字符编码较短,使用频率低的编码较长,这种方法可以提高压缩率,节省空间,也能提高运算和通信速度。
- 不能有二义性:任何一个字符的编码不能是另一个字符的前缀,即前缀码特性,例如不能有“10”和“101”这样的编码。
哈夫曼编码的基本思想:以字符的使用频率作为权值构建一颗哈夫曼树,然后利用哈夫曼树对字符进行编码。
假设这 6 个字符出现的频率从高到低依次是 a、b、c、d、e、f。
| 字符 | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| 出现频率 | 32 | 25 | 18 | 13 | 7 | 5 |
构造一棵哈夫曼树:将要编码的字符作为叶子节点,它们对应的频率作为其权值,初始每个字符都是一个单独的树,以自底向上的方式合并,直到只剩一棵树为止。

采取的贪心策略:每次从树的集合中取出没有父节点且权值最小的两棵树作为左右子树,构造一棵新树,新树根节点的权值为其左右孩子节点权值之和,将新树插入到树的集合中,继续使用贪心策略进行选择,直到树的集合中只剩一棵树时结束。
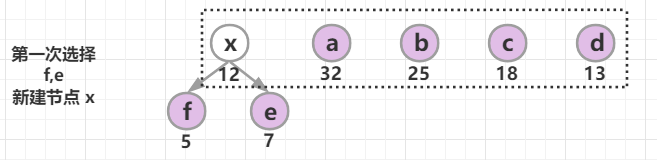
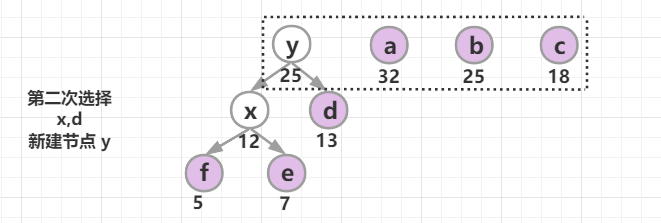
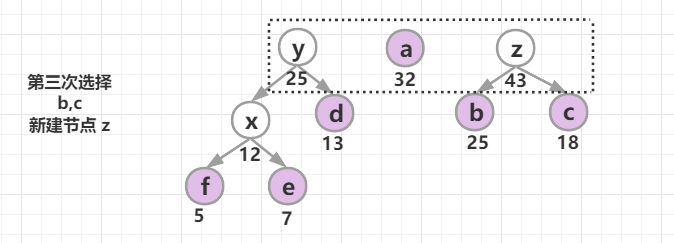
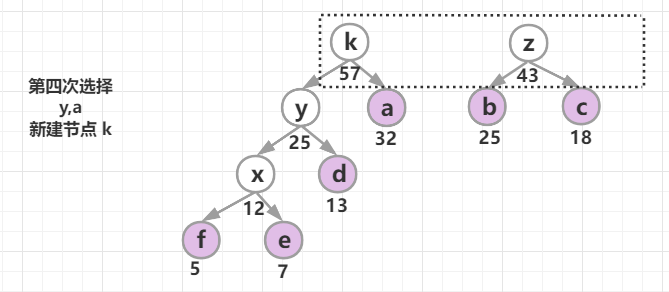
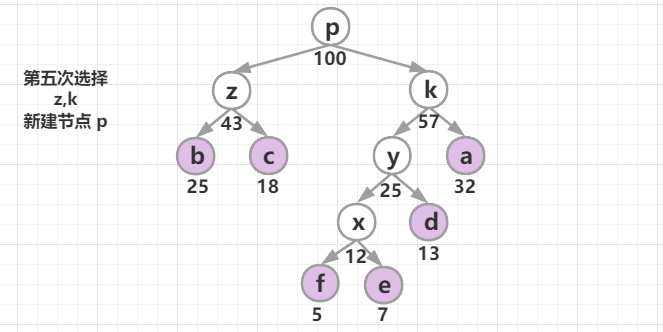
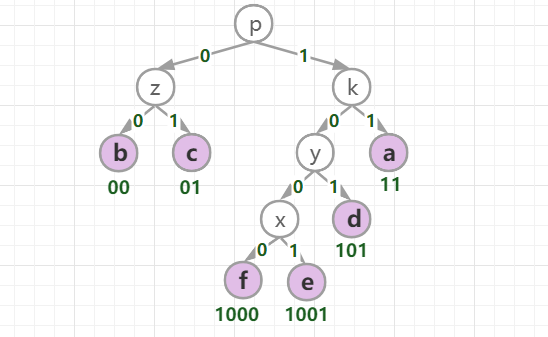
哈夫曼树构建成功后,约定左分支(的边)编码为0,右分支(的边)编码为1,那从根节点到叶节点的路径就是叶节点对应字符的霍夫曼编码。
5. 回溯算法
回溯算法(Back Tracking)也叫试探法,解决问题时,每进行一步,都是抱着试试看的态度,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。深度优先搜索算法利用的是回溯算法思想。
回溯算法的思想非常简单,大部分情况下,都是用来解决广义的搜索问题,也就是,从一组可能的解中,选择出一个满足要求的解。回溯算法非常适合用递归来实现,在实现的过程中,剪枝操作是提高回溯效率的一种技巧。利用剪枝,我们并不需要穷举搜索所有的情况,从而提高搜索效率。
剪枝:在不符合条件的情况下尽早结束该路劲的遍历。
回溯算法思想下,需要清晰的找出三个要素:选择 (Options),限制 (Restraints),结束条件 (Termination)。
- 回溯算法的一般步骤:
- 针对所给问题,定义问题的解空间,它至少包含问题的一个(最优)解。
- 确定易于搜索的解空间结构,使得能用回溯法方便地搜索整个解空间。
- 以深度优先的方式搜索解空间,并且在搜索过程中用剪枝函数避免无效搜索。
代码模板:
1 | /** |
5.1 回溯算法的经典应用:0-1 背包问题
问题:我们有一个背包,背包总的承载重量是wkg。现在我们有n个物品,每个物品不同重量,并且不可分割。在满足背包背包承重的前提下,背包中物品总重量的最大值是多少呢?
解析:n个物品,对于每个物品有装或者不装两种选择,所以是222…2=2^n种装法,去掉总重量超过wkg的,从剩下的装法中选择总重量最接近wkg的。
这里就可以用回溯的方法。我们可以把物品依次排列,整个问题就分解为了 n 个阶段,每个阶段对应一个物品怎么选择。先对第一个物品进行处理,选择装进去或者不装进去,然后再递归地处理剩下的物品。直接看代码:
1 | /** |
6. 动态规划
动态规划(Dynamic Programming,简称DP)常用于求解最优性质的问题(这类问题可能有许多解,希望找到最优值的解)。
动态规划算法与分治算法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。不同的是,动态规划避免了重复计算相同子问题,用一个表来记录所有已解的子问题的答案。不管该子问题以后是否被用到,只要它被计算过,就将其结果填入表中。这就是动态规划法的基本思路。具体的动态规划算法多种多样,但它们具有相同的填表格式。
动态规划适合解决的问题的模型定义为多阶段决策最优解模型:
解决问题的过程,需要经历多个决策阶段。每个决策阶段依赖于当前状态(每个子问题的解叫做一个状态)。当各个阶段决策确定后,就组成一个决策序列。经过这组决策序列,能够产生最终期望求解的最优值。
- 动态规划的三个特征分别是最优子结构、无后效性和重复子问题:
- 最优子结构:问题的最优解包含子问题的最优解。反过来说就是,可以通过子问题的最优解,推导出问题的最优解。即后面阶段的状态可以通过前面阶段的状态推导出来。
- 无后效性:某阶段状态一旦确定,就不受之后阶段的决策影响。即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
- 重复子问题:不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态。即重复子问题可能会被重复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,从而获得较高的效率。
6.1 0-1 背包问题升级版
问题:我们有一个背包,背包总的承载重量是wkg。现在我们有n个物品,每个物品不同重量、不同价值、并且不可分割。在满足背包背包承重的前提下,背包中可装入物品的总价值最大是多少呢?
解析:引入物品价值这一变量,这个问题依旧可以用回溯算法来解决,代码:
1 | /** |
针对上面的代码,我们画出递归树。在递归树中,每个节点表示一个状态。现在我们需要3个变量(i, sumW, sumV)来表示一个状态。其中,i表示即将要决策第i个物品是否装入背包,sumW表示当前背包中物品的总重量,sumV表示当前背包中物品的总价值。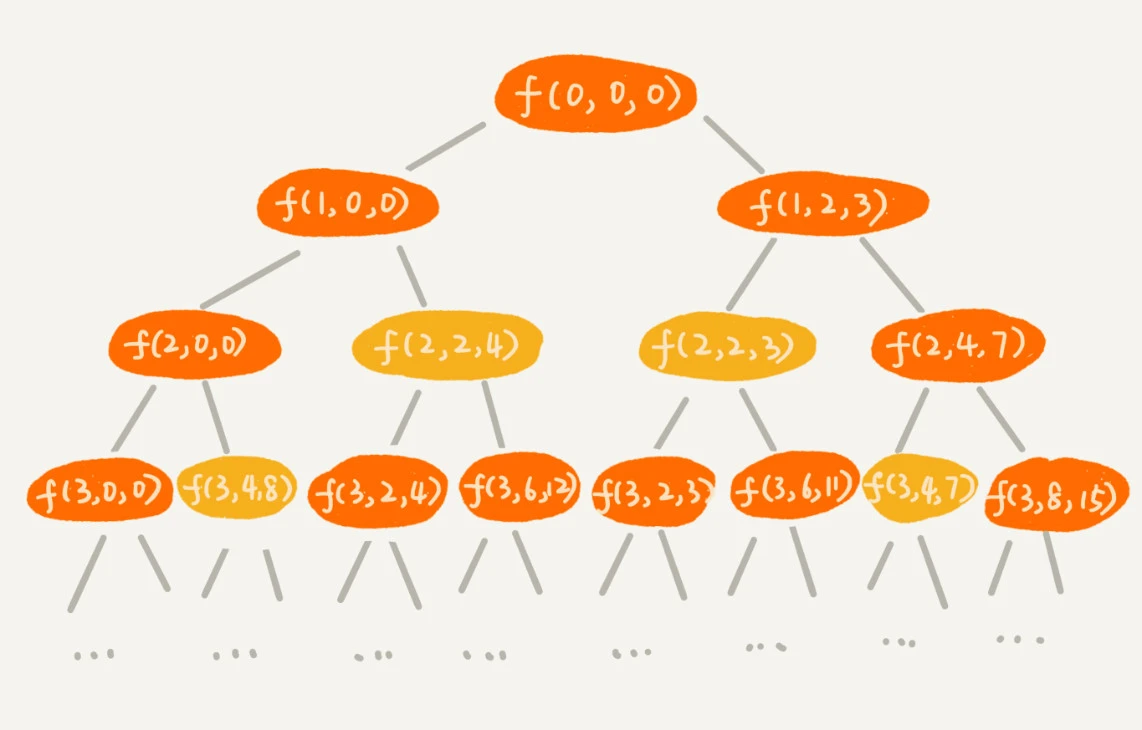
我们发现,在递归树中,有几个节点的i和sumW是完全相同的,比如f(2,2,4)和f(2,2,3)。在背包中物品总重量一样的情况下,f(2,2,4)这种状态对应的物品总价值更大,我们可以舍弃f(2,2,3) 这种状态,只需要沿着f(2,2,4)这条决策路线继续往下决策就可以。
也就是说,对于(i, sumW)相同的不同状态,那我们只需要保留sumV值最大的那个,继续递归处理,其他状态不予考虑。
我们把状态设置为背包中的价值,用一个二维数组 dp[n][w+1]来记录。我们把每一层中(i, sumW)重复的状态(节点)合并,只记录sumV值最大的那个状态,然后基于这些状态来推导下一层的状态。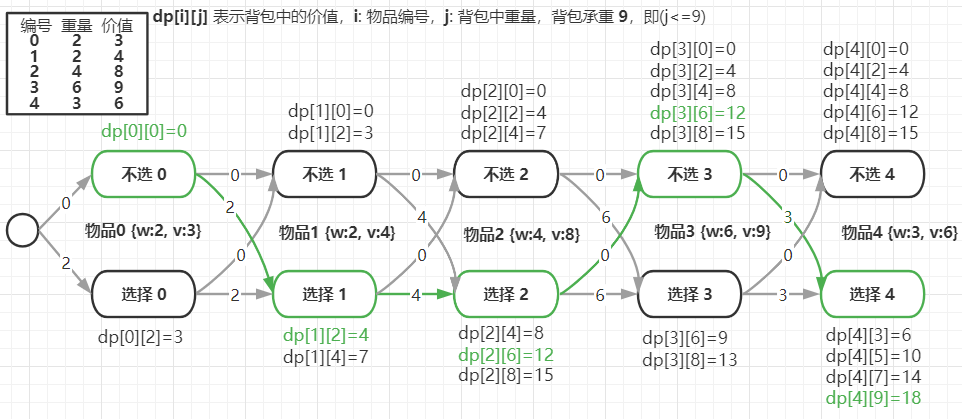
重量相同时保留值最大的状态填入表格,最优解即是dp[4][9]=18: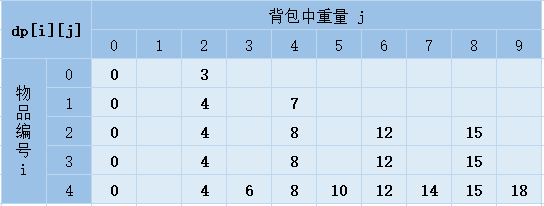
我们把这个动态规划的过程翻译成代码:
1 | /** |
6.2 动态规划解题思路
解决动态规划问题,一般有两种思路。我把它们分别叫作,状态转移表法和状态转移方程法。
6.2.1 状态转移表法
一般能用动态规划解决的问题,都可以使用回溯算法的暴力搜索解决。我们可以先用简单的回溯算法解决,然后定义状态,每个状态表示一个节点,然后对应画出递归树。从递归树中,我们很容易可以看出来,是否存在重复子问题,以及重复子问题是如何产生的。以此来寻找规律,看是否能用动态规划解决。
找到重复子问题之后,接下来,我们有两种处理思路,第一种是直接用回溯加“备忘录”的方法,来避免重复子问题。从执行效率上来讲,这跟动态规划的解决思路没有差别。第二种是使用动态规划的解决方法,状态转移表法。
状态转移表法的工作思路:先画出一个状态表。状态表一般都是二维的,所以你可以把它想象成二维数组。其中,每个状态包含三个变量,行、列、数组值。我们根据决策的先后过程,从前往后,根据递推关系,分阶段填充状态表中的每个状态。最后,我们将这个递推填表的过程,翻译成代码,就是动态规划代码了。
状态转移表法解题思路大致可以概括为,回溯算法实现 - 定义状态 - 画递归树 - 找重复子问题 - 画状态转移表 - 根据递推关系填表 - 将填表过程翻译成代码。
6.2.2 状态转移方程法
状态转移方程法有点类似递归的解题思路。我们需要分析,某个问题如何通过子问题来递归求解,也就是所谓的最优子结构。根据最优子结构,写出递归公式,也就是所谓的状态转移方程。有了状态转移方程,代码实现就非常简单了。一般情况下,我们有两种代码实现方法,一种是递归加“备忘录”,另一种是迭代递推。
状态转移方程是解决动态规划的关键。如果我们能写出状态转移方程,那动态规划问题基本上就解决一大半了,而翻译成代码非常简单。但是很多动态规划问题的状态本身就不好定义,状态转移方程也就更不好想到。
状态转移方程法的大致思路可以概括为,找最优子结构 - 写状态转移方程 - 将状态转移方程翻译成代码。
7. 经典算法思想比较分析
实际上枚举思想是最接近人的思维方式,在更多的时候是用来帮助我们去「理解问题」,而不是「解决问题」。
递归思想其实就是一个「套娃」过程。使用时要明确终止条件,及时止损。多数算法的编码实现都要用到递归,但递归代码也有很多弊端,要根据实际情况来选择是否需要用递归的方式来实现。
贪心、回溯、动态规划可以抽象成「多阶段决策最优解」模型,而分治算法解决的问题尽管大部分也是最优解问题,但是,大部分都不能抽象成多阶段决策模型。分治算法通过层层粒度上的划分,将原问题划分为最小的子问题,然后再向上依次得到更高粒度的解。先从上而下,再从下而上。「先分解,再求解,再合并」。
回溯算法是个“万金油”。基本上能用的动态规划、贪心解决的问题,我们都可以用回溯算法解决。回溯算法相当于穷举搜索。穷举所有的情况,然后对比得到最优解。不过,回溯算法的时间复杂度非常高,是指数级别的,只能用来解决小规模数据的问题。
动态规划比回溯算法高效,但是需要满足三个特征,最优子结构、无后效性和重复子问题。在重复子问题这一点上,动态规划和分治算法的区分非常明显。分治算法要求分割成的子问题,不能有重复子问题,而动态规划正好相反,动态规划之所以高效,就是因为回溯算法实现中存在大量的重复子问题。
贪心算法实际上是动态规划算法的一种特殊情况。它解决问题起来更加高效,代码实现也更加简洁。不过,它可以解决的问题也更加有限。它能解决的问题需要满足三个条件,最优子结构、无后效性和贪心选择性(这里我们不怎么强调重复子问题)。其中,最优子结构、无后效性跟动态规划中的无异。“贪心选择性”的意思是,通过局部最优的选择,能产生全局的最优选择。每一个阶段,我们都选择当前看起来最优的决策,所有阶段的决策完成之后,最终由这些局部最优解构成全局最优解。
原文链接: http://chaooo.github.io/2022/07/25/data-structure-algorithm-method.html
版权声明: 转载请注明出处.