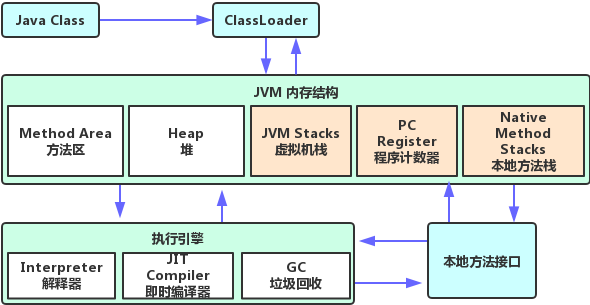
Java 虚拟机运行时数据区
- 程序计数器(Program Counter Register)
- 本地方法栈(Native Method Stack)
- Java 虚拟机栈(VM Stack)
- Java 堆(Heap)(线程共享)
- 方法区(Method Area)(线程共享)
Java 运行过程
Java源代码经过Javac编译成 字节码(bytecode).class文件;- 在运行时,通过 虚拟机(JVM)内嵌的解释器 将
字节码转换成为最终的机器码。
常见的 JVM,都提供了 JIT(Just-In-Time)编译器,也就是通常所说的动态编译器,JIT 能够在运行时将热点代码编译成机器码,所以准确的说 Java 代码会
解释执行或编译执行。
1.程序计数器(Program Counter Register)
- 线程私有
- 不会内存溢出
- 作用:记住下一条 JVM 指令的执行地址。
2.Java 虚拟机栈(VM Stack)
- 线程私有
- LIFO(后进先出)
- 存储栈帧,支撑 Java 方法的调用、执行和退出
- 可能出现 OutOfMemoryError 异常(如果被设计成动态扩展,而扩展又未申请到足够的内存抛出)和 StackOverflowError 异常(如线程请求的栈深度大于最大深度抛出)
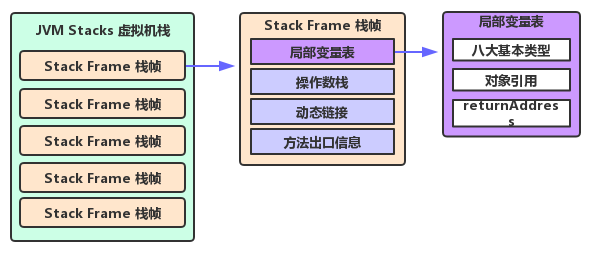
2.1 栈帧(Frame)
- Java 虚拟机栈中存储的内容,它被用于存储数据和部分过程结构的数据结构,同时也被用来处理动态链接、方法返回值 和 异常分派
- 一个完整的栈帧包含:局部变量表、操作数栈、动态连接信息、方法正常完成和异常完成的信息
- 每个栈由多个栈帧组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
2.2 局部变量表
- 由若干个 Slot 组成,长度由编译期决定
- 单个 Slot 可以储存一个类型为 boolean、byte、char、short、float、reference、returnAddress 的数据,两个 Slot 可以存储一个类型为 long 或 double 的数据
- 局部变量表用于方法间参数的传递,以及方法执行过程中存储基础数据类型的值和对象的引用
2.3 操作数栈
- 一个后进先出栈,由若干个 Entry 组成,长度由编译期决定
- 单个 Entry 即可以存储一个 Java 虚拟机中定义的任意数据类型的值,包括 long 和 double 类型,但是存储 long 和 double 类型的 Entry 深度为 2,其他类型深度为 1
- 在方法执行过程中,栈帧用于存储计算参数和计算结果;在方法调用时,操作数栈也用来准备调用方法的参数以及接收方法返回结果
2.4 栈的内存溢出(StackOverflowError)
- 栈帧过多导致内存溢出(方法的递归调用)
- 栈帧过大导致内存溢出
- JSON 数据转换可能导致内存溢出(可用@JsonIgnore 忽略不能转换的属性)
2.5 线程诊断
- 案例 1:cpu 占用过高
- Linux 下,
top打印所有进程,筛选 cpu 占用高的进程号,如:32655 - 用
ps H -eo pid,tid,%cpu | grep 32655打印 32655 的所有线程,定位到具体 cpu 占用过高的线程 jstack 进程id打印该线程的所有线程详情- 将线程 id 换算成 16 进制,对比打印出的线程详情,定位到具体线程,进一步定位到源代码具体代码行号。
- Linux 下,
- 案例 2:程序运行很长时间没有结果
- 前面步骤同上,
jstack 进程id打印该线程的所有线程详情 - 在最后一段找到了 Found one Java-level deadlock,定位死锁的具体行号。
- 前面步骤同上,
3.本地方法栈(Native Method Stack)
- 线程私有
- LIFO(后进先出)
- 支撑 Native 方法的调用、执行和退出
- 可能出现 OutOfMemoryError 异常 和 StackOverflowError 异常
- 有一些虚拟机(如 HotSpot)将 Java 虚拟机栈和本地方法栈合并实现
3.1 Java 虚拟机栈和本地方法栈可能发生的异常情况:
- 如果线程请求分配的栈容量超过 Java 虚拟机栈允许的最大容量时,Java 虚拟机将会抛出一个 StackOverflowError 异常
- 如果 Java 虚拟机栈可以动态扩展,并且扩展的动作已经尝试过,但是目前无法申请到足够的内存去完成扩展,或者在建立新的线程时没有足够的内存去创建对应的虚拟机栈,那么 Java 虚拟机将会抛出一个 OutOfMemoryError 异常。
4.Java 堆(Heap)
- 全局共享
- 通常是 Java 虚拟机中最大的一块内存区域
- 作用是作为 Java 对象的主要存储区域(通过 new 创建的对象都会使用堆内存)
- 有垃圾回收机制
4.1 Java 堆可能发生的异常
- 如果实际所需的堆超过了自动内存管理系统能提供的最大容量,那 Java 虚拟机将会抛出一个 OutOfMemoryError 异常。
4.2 堆内存诊断
- jps 工具:查看当前系统中有哪些 Java 进程
- jmap 工具:查看堆内存占用情况
jmap -head 进程id - jconsole 工具:图形界面,多功能的监测工具,可以连续监测
- 案例:垃圾回收后,内存占用仍然很高
- jps 工具定位进程,
jmap -head 进程id查看堆使用情况, - 可以用 jconsole 工具手动执行 GC
- 用 jvirsualvm 抓取堆 dump(快照,抓取堆里面有哪些类型的对象及个数等信息)
- jps 工具定位进程,
4.3 字符串常量池 (StringTable)
- 在 JDK6.0 及之前版本,字符串常量池是放在 Perm Gen 区(也就是方法区)中;
- 在 JDK7.0 版本,字符串常量池被移到了堆中
- 字符串手动入池: 调用
String.intern()
5.方法区(Method Area)
- 全局共享
- 作用是存储 Java 类的结构信息
- JVMS 不要求该区域实现自动内存管理,但是商用 Java 虚拟机都能够自动管理该区域内存
- 在 JDK1.8 后,方法区由元空间实现
方法区内存溢出场景:spring、mabatis 等动态加载类的场景使用不当会导致方法区内存溢出
5.1 运行时常量池
- 全局共享
- 是方法区的一部分
- 作用是存储 Java 类文件常量池中的符号信息
- 可能出现 OutOfMemoryError 异常
5.2 永久代与方法区
- 在 JDK1.2~6,HotSpot 使用永久代实现方法区
- 在 JDK1.7,开始移除(符号表被到 Native Heap,字符串常量和类的静态引用被移到 Java Head 中)
- 在 JDK1.8,永久代被元空间(Metaspace)所替代
6.直接内存
- 全局共享
- 并非 JVMS 定义的标准 Java 运行时内存区域, 属于操作系统内存
- JDK1.4 引入 NIO,目的是避免 Java 堆 和 Native 堆 中来回 复制数据 带来的性能损耗。
- 能被自动管理,但是在检测手段上可能会由一些简陋
- 可能出现 OutOfMemoryError 异常
- 常用于 NIO 操作时,用于数据缓冲区
- 分配回收成本高,但读写性能高,不受 JVM 内存回收管理
7.可回收对象的判定
- 引用计数法:给对象添加一个引用计数器,每当有一个地方引用它时,计数器就+1,当引用失效就-1,任何时候计数器为 0 时就是可回收对象。
- 可达性分析:通过一系列名为 GC Roots 的对象作为起始点,从这些根节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到 GC Roots 没有任何引用链相连时,则称该对象是不可达的。
目前主流 Java 虚拟机中并没有选用引用计数法,其中最重要的原因是它很难解决循环引用问题
7.1 Java 语言中的 GC Roots
- 在虚拟机栈(栈帧中的本地变量表)中的引用的对象。
- 在方法区中的类静态属性引用的对象。
- 在方法区中的常量引用的对象。
- 在本地方法栈中 JNI(即一般说的 Native 方法)的引用对象。
7.2 Java 引用类型
- 强引用:Java 中默认声明的就是强引用
- 垃圾回收器将永远不会回收被「强引用」对象,哪怕内存不足时,JVM 也会直接抛出 OutOfMemoryError,不会去回收。可以赋值为 null 中断强引用。
- 软引用(SoftReference):用来描述一些非必需但仍有用的对象,用 java.lang.ref.SoftReference 类来表示软引用
- 垃圾回收后,在内存不足时会再次触发垃圾回收,回收「软引用」对象,仍不足,才会抛出内存溢出异常。可以配合引用队列来释放软引用自身。
- 弱引用(WeakReference):用 java.lang.ref.WeakReference 来表示弱引用
- 垃圾回收器将永远都会回收被「弱引用」对象,无论内存是否足够。可以配合引用队列来释放弱引用自身。
- 虚引用(PhantomReference):最弱的一种引用关系,用 PhantomReference 类来表示
- 必须配合引用队列使用,主要配合 ByteBuffer 使用,被引用对象回收时,会将虚引用入队,由 Reference Handler 线程调用虚引用相关方法释放直接内存。
8.垃圾回收算法
- 标记清除算法(Mark-Sweep)
- 标记整理算法(Mark-Compact)
- 复制算法(copying)
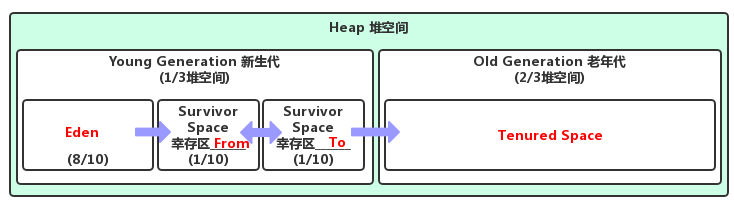
8.1 分代垃圾回收(Java 堆分为新生代和老年代)
- 对象首先分配在新生代的
Eden区 - 新生代空间不足时,触发
Minor GC,Eden 区和 From 幸存区(Survivor)存活的对象使用 coping 复制到 To 幸存区中,存活的年龄+1 并且交换 From 和 To。 - Minor GC 会引发
STW(Stop the world),暂停其他用户的线程,等垃圾回收结束后,用户线程才恢复运行 - 当对象
寿命超过阈值时,会晋升至老年代,最大寿命 15(4bit) - 当老年代空间不足,会先尝试触发 Minor GC,如果之后空间仍不足,那么触发
Full GC,STW 的时间更长
8.2 相关 JVM 参数
- 堆初始大小:
-Xms - 堆最大大小:
-Xmx或-XX:MaxHeapSize=size - 新生代大小:
-Xmn或(-XX:NewSize=size + -XX:MaxNewSize=size) - 幸存区比例(动态):
-XX:InitialSurvivorRatio=ratio和-XX:+UseAdaptiveSizePolicy - 幸存区比例:
-XX:SurvivorRatio=ratio - 晋升阈值:
-XX:MaxTenuringThreshold=threshold - 晋升详情:
-XX:+PrintTenuringDistribution - GC 详情:
-XX:+PrintGCDetils -verbose:gc - FullGC 前 MinorGC:
-XX:+ScavengeBeforeFullGC
9.垃圾回收器
- 串行(开启:
-XX:+UseSerialGC=Serial + SerialOld)- 单线程
- 适合堆内存较小,适合个人电脑
- 吞吐量优先
- 多线程
- 堆内存较大,多核 CPU
- 让单位时间内,总 STW 的时间最短
- 响应时间优先
- 多线程
- 堆内存较大,多核 CPU
- 尽量让单次 STW 的时间最短
9.1 吞吐量优先(并行)回收器
- 开启(默认开启):
-XX:+UseParallelGC~-XX:+UseParallelOldGC - 动态调整堆大小:
-XX:+UseAdaptiveSizePolicy - 目标吞吐量:
-XX:GCTimeRatio=ratio - 最大暂停时间的目标值:
-XX:MaxGCPauseMillis=ms - 线程数:
-XX:ParallelGCThreads=n
9.2 响应时间优先(并发)回收器
可以和用户线程并发执行,工作在老年代
- 开启:
-XX:+UseConcMarkSweepGC配合-XX:UseParNewGC~SerialOld - 并行和并发线程数:
-XX:ParallelGCThreads=n~-XX:ConsGCThreads=threads - 回收时机(内存占比):
-XX:CMSInitiatingOccupancyFraction=percent - 重新标记前对新生代先做垃圾回收:
-XX:+CMSScavengeBeforeRemark
9.3 G1(Garbage First)(并发)
- G1 回收器 适用场景
- 同时注重 吞吐量(Throughput)和低延迟(Low latency),默认暂停目标是 200ms
- 超大堆内存,会将堆划分为多个大小相等的区域(Region)
- 整体上是标记+整理算法,两个区域之间是复制算法
- 相关 JVM 参数
- 开启(JDK9 默认):
-XX:+UseG1GC - 区域大小:
-XX:G1HeapRegionSize=size - 最大暂停时间:
-XX:MaxGCPauseMillis=time
- 开启(JDK9 默认):
- G1 垃圾回收阶段(三个阶段循环)
- **
Young Collection**:新生代 GC(会 STW) - **
Young Collection + Concurrent Mark**:- 在 YoungGC 时会进行
GC Root的初始标记 - 老年代占用堆空间比例达到阈值值,进行并发标记(不会 STW),由下面的 JVM 参数决定
-XX:InitiatingHeadOccupancyPercent=percent(默认 45%)
- 在 YoungGC 时会进行
- **
Mixed Collection**:会对 Eden、Survivor、Old 进行全面垃圾回收- 最终标记(Remark)会 STW
- 拷贝存活(Evacuation)会 STW
- 为达到最大暂停时间短的目标,Old 区是优先回收垃圾最多的区域
- **
9.4 Minor GC 和 Full GC
- SerialGC
- 新生代内存不足:Minor GC
- 老年代内存不足:Full GC
- ParallelGC
- 新生代内存不足:Minor GC
- 老年代内存不足:Full GC
- CMS
- 新生代内存不足:Minor GC
- 老年代内存不足:分两种情况(回收速度高于内存产生速度不会触发 Full GC)
- G1
- 新生代内存不足:Minor GC
- 老年代内存不足:分两种情况(回收速度高于内存产生速度不会触发 Full GC)
Minor GC:当 Eden 区满时,触发 Minor GCFull GC:
- System.gc()方法的调用
- 老年代空间不足
- 方法区空间不足
- 通过 Minor GC 后进入老年代的平均大小大于老年代的可用内存
- 由 Eden 区、From 幸存区 向 To 幸存区 复制时,对象大小大于 To 区可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
10.垃圾回收调优
- 调优领域:内存、锁竞争、CPU 占用、IO
- 调优目标:「低延迟」还是「高吞吐量」(高吞吐量:ParallelGC,低延迟:CMS,G1,ZGC)
- 最快的 GC 是不发生 GC:查看 Full GC 前后的内存占用(内存数据太多?数据表示太臃肿?内存泄漏?)
- 新生代调优:new 操作内存分配廉价、死亡对象回收代价是零、大部分对象用过即死、MinorGC 时间远低于 FullGC
10.1 新生代调优
- 理想情况:新生代能容纳所有「并发量*(请求-响应)」的数据
- 幸存区大到能够保留「当前活跃对象+需要晋升对象」
- 「晋升阈值配置」得当,让长时间存活的对象尽快晋升
- 调整最大晋升阈值:
-XX:MaxTenuringThreshold=threshold - 打印晋升详情:
-XX:+PrintTenuringDistribution
- 调整最大晋升阈值:
10.2 老年代调优
以 CMS 为例:
- CMS 的老年代内存越大越好(避免浮动垃圾引起的并发失败)
- 先尝试不做调优,如果没有 FullGC 那么已经 OK,否则先尝试调优新生代
- 观察发生 Full GC 时老年代内存占用,将老年代内存预设调大 1/4~1/3
-XX:CMSInitiatingOccupancyPercent=percent
10.3 调优案例
- 案例 1:FullGC 和 MinorGC 频繁
- 可能原因:空间紧张,若业务高峰期时,新生代空间紧张,幸存区的晋升阈值会降低,大量本来生存短对象晋升老年区,进一步触发老年代 FullGC 的频繁发生
- 解决方法:经过分析,观察堆空间大小,先试着增大新生代内存,同时增大幸存区的空间以及晋升阈值。
- 案例 2:请求高峰期发生了 FullGC,单次暂停时间特别长(CMS)
- 查看日志,看 CMS 哪个阶段暂停时间长(重新标记阶段),解决:打开开关参数 CMSScavengeBeforeRemark
- 重新标记前对新生代先做垃圾回收:
-XX:+CMSScavengeBeforeRemark
10.4 G1 调优最佳实践
- 不要设置新生代和老年代的大小
- G1 收集器在运行的时候会调整新生代和老年代的大小。通过改变代的大小来调整对象晋升的速度以及晋升年龄,从而达到我们为收集器设置的暂停时间目标。设置了新生代大小相当于放弃了 G1 为我们做的自动调优。我们需要做的只是设置整个堆内存的大小,剩下的交给 G1 自己去分配各个代的大小。
- 不断调优暂停时间指标
- 通过 XX:MaxGCPauseMillis=x 可以设置启动应用程序暂停的时间,G1 在运行的时候会根据这个参数选择 CSet 来满足响应时间的设置。一般情况下这个值设置到 100ms 或者 200ms 都是可以的(不同情况下会不一样),但如果设置成 50ms 就不太合理。暂停时间设置的太短,就会导致出现 G1 跟不上垃圾产生的速度。最终退化成 Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。
- 关注 Evacuation Failure
- Evacuation Failure 类似于 CMS 里面的晋升失败,堆空间的垃圾太多导致无法完成 Region 之间的拷贝,于是不得不退化成 Full GC 来做一次全局范围内的垃圾收集。
原文链接: http://chaooo.github.io/2019/08/23/jvm-stack.html
版权声明: 转载请注明出处.