哈希算法(Hash)又称摘要算法(Digest),它的作用是:对任意一组输入数据进行计算,得到一个固定长度的输出摘要。
哈希算法最重要的特点就是:相同的输入一定得到相同的输出;不同的输入大概率得到不同的输出。
哈希算法的目的就是为了验证原始数据是否被篡改。
1 | // Java字符串的hashCode()就是一个哈希算法,它的输入是任意字符串,输出是固定的4字节int整数: |
哈希碰撞是指,两个不同的输入得到了相同的输出。一个安全的哈希算法必须满足:碰撞概率低,不能猜测输出。
1 | "AaAaAa".hashCode(); // 0x7460e8c0 |
1. 常用的哈希算法
| 算法 | 输出长度(位) | 输出长度(字节) |
|---|---|---|
| MD5 | 128 bits | 16 bytes |
| SHA-1 | 160 bits | 20 bytes |
| RipeMD-160 | 160 bits | 20 bytes |
| SHA-256 | 256 bits | 32 bytes |
| SHA-512 | 512 bits | 64 bytes |
根据碰撞概率,哈希算法的输出长度越长,就越难产生碰撞,也就越安全。
2. 哈希算法的应用
哈希算法的应用非常非常多,这里介绍最常见的七个,分别是安全加密、唯一标识、数据校验、散列函数、负载均衡、数据分片、分布式存储。
2.1 安全加密
最常用于加密的哈希算法是 MD5(MD5 Message-Digest Algorithm,MD5 消息摘要算法)和 SHA(Secure Hash Algorithm,安全散列算法)。
除了这两个之外,当然还有很多其他加密算法,比如计算机网络的SSL/TLS协议里面的对称加密(AES)、非对称加密(RSA)。
安全加密的关键点:①很难根据哈希值反向推导出原始数据;②散列冲突的概率要很小。
不管是什么哈希算法,只能尽量减少碰撞冲突的概率,理论上是无法做到完全不冲突的。
一般情况下,哈希值越长的哈希算法,散列冲突的概率越低。
没有绝对安全的加密。任何哈希算法都会出现散列冲突,但是这个冲突概率非常小。越是复杂哈希算法越难破解,但同样计算时间也就越长。所以,选择哈希算法的时候,要权衡安全性和计算时间来决定用哪种哈希算法。
2.2 唯一标识
哈希算法可以对大数据做信息摘要,通过一个较短的二进制编码来表示很大的数据。
比如URL字段或者图片字段要求不能重复,这个时候就可以通过哈希算法对这个数据取唯一标识,或者说信息摘要(比如MD5处理)。
此外,还可以对文件之类的二进制数据做MD5处理,作为唯一标识,这样判定重复文件的时候更快捷。
2.3 数据校验
网络传输数据不安全,传输数据的过程中,数据可能被宿主机篡改,或数据丢失,所以需要校验文件的安全,正确,完整性。
因为哈希算法对数据很敏感,只要文件块的内容有一丁点儿的改变,最后计算出的哈希值就会完全不同;所以在文件块下载完后,使用相同的哈希算法,对于文件计算,判断是否相同。
2.4 散列函数
散列函数是设计一个散列表的关键。它直接决定了散列冲突的概率和散列表的性能。不过,散列函数对于散列算法冲突的要求要低很多。即便出现个别散列冲突,只要不是过于严重,我们都可以通过开放寻址法或者链表法解决。
散列函数中用到的散列算法,更加关注散列后的值是否能平均分布,也就是,一组数据是否能均匀地散列在各个槽中。除此之外,散列函数执行的快慢,也会影响散列表的性能,所以,散列函数用的散列算法一般都比较简单,比较追求效率。
2.5 负载均衡
负载均衡算法有很多,比如轮询、随机、加权轮询等。利用哈希算法替代映射表,可以实现一个会话粘滞的负载均衡策略。
我们可以通过哈希算法,对客户端 IP 地址或者会话 ID 计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。 这样,我们就可以把同一个 IP 过来的所有请求,都路由到同一个后端服务器上。
2.6 数据分片
针对海量数据的处理问题,通过哈希算法对处理的海量数据进行分片,多机分布式处理。借助这种分片的思路,可以突破单机内存、CPU 等资源的限制。
2.7 分布式存储
在分布式存储应用中,利用一致性哈希算法,可以解决缓存等分布式系统的扩容、缩容导致数据大量搬移的难题。
2.7.1 一致性哈希算法
一致性哈希算法是对2^32进行取模运算,是一个固定的值。即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图:
一致性哈希要进行的两步哈希:
- 对存储节点进行哈希计算,也就是对存储节点做哈希映射,比如根据节点的 IP 地址进行哈希;
- 当对数据进行存储或访问时,对数据进行哈希映射;
- 所以,一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上。
如下图,已经有3个节点经过哈希计算,映射到了哈希环上相应的位置,有三个数据进行哈希映射到节点上;
①首先,对 key 进行哈希计算,确定此 key 在环上的位置;
②然后,从这个位置沿着顺时针方向走,遇到的第一节点就是存储 key 的节点。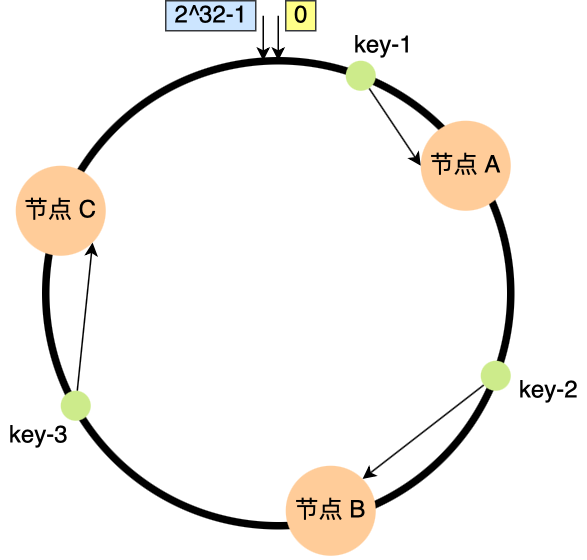
假设节点数量从 3 增加到了 4,新的节点 D 经过哈希计算后映射到了下图中的位置;
可以看到,key-1、key-3 都不受影响,只有 key-2 需要被迁移节点 D。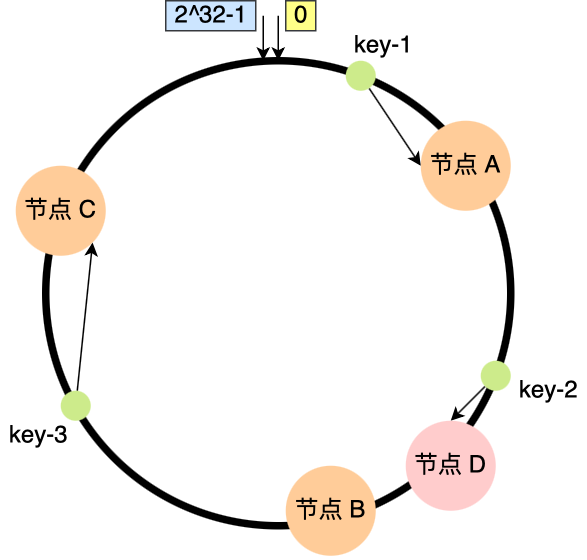
假设节点数量从 3 减少到了 2,比如将节点 A 移除;
你可以看到,key-2 和 key-3 不会受到影响,只有 key-1 需要被迁移节点 B。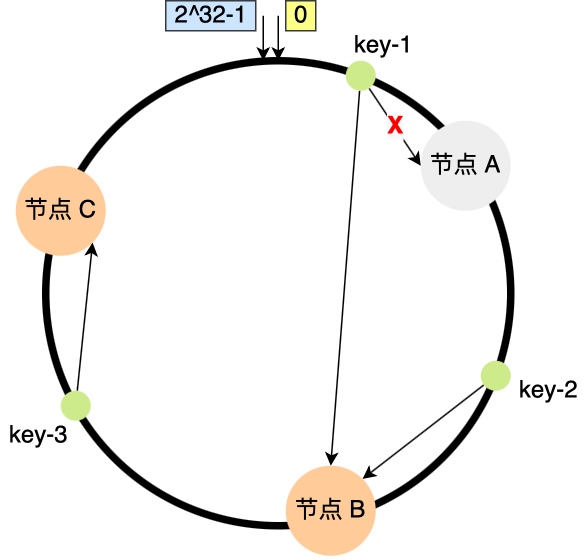
在一致性哈希算法中,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
2.7.2 虚拟节点
一致性哈希算法虽然减少了数据迁移量,但是并不保证节点能够在哈希环上分布均匀,这样就会带来一个问题,会有大量的请求集中在一个节点上。在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
如下图中 3 个节点的映射位置都在哈希环的右半边: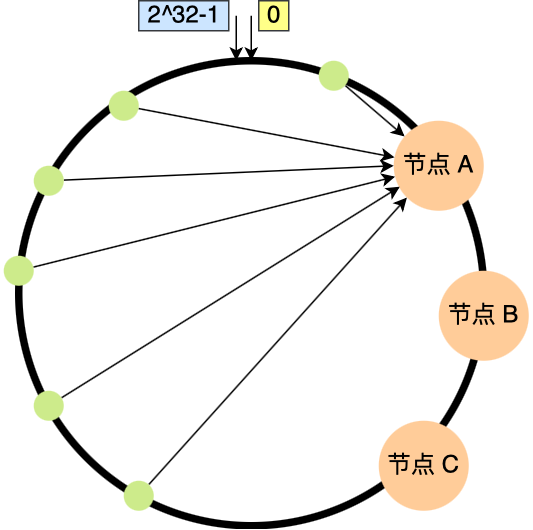
要想解决节点能在哈希环上分配不均匀的问题,就是要有大量的节点,节点数越多,哈希环上的节点分布的就越均匀。
这个时候我们就加入虚拟节点,也就是对一个真实节点做多个副本。
具体做法是,不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
比如对每个节点分别设置 3 个虚拟节点,引入虚拟节点后,原本哈希环上只有 3 个节点的情况,就会变成有 9 个虚拟节点映射到哈希环上,哈希环上的节点数量多了 3 倍。
节点数量多了后,节点在哈希环上的分布就相对均匀了。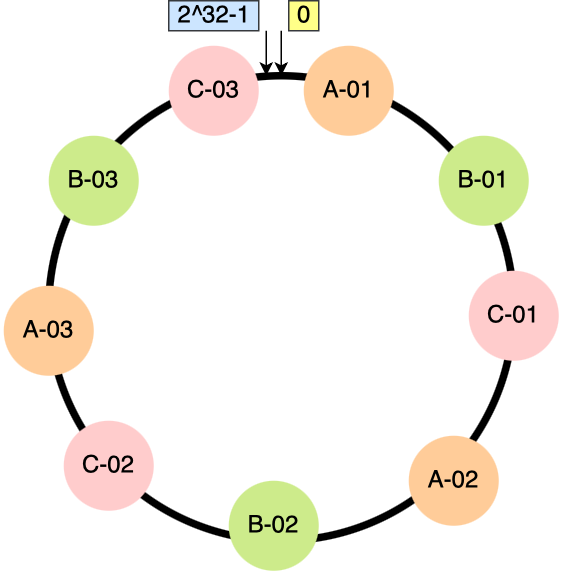
这时候,如果有访问请求寻址到「A-01」这个虚拟节点,接着再通过「A-01」虚拟节点找到真实节点 A,这样请求就能访问到真实节点 A 了。
虚拟节点除了会提高节点的均衡度,还会提高系统的稳定性。当节点变化时,会有不同的节点共同分担系统的变化,因此稳定性更高。
有了虚拟节点后,还可以为硬件配置更好的节点增加权重,比如对权重更高的节点增加更多的虚拟机节点即可。
因此,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
2.7.3 分布式存储的哈希算法总结
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
但是一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
引入虚拟节点后,可以会提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
原文链接: http://chaooo.github.io/2022/03/25/data-structure-hashalgorithm.html
版权声明: 转载请注明出处.