跳表(Skip List)是一个动态数据结构(链表加多级索引),可以支持快速地插入、删除、查找操作的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
1. 跳表的演化
跳表的原始链表是一个有序单链表,如果要想在其中查找某个数据,只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。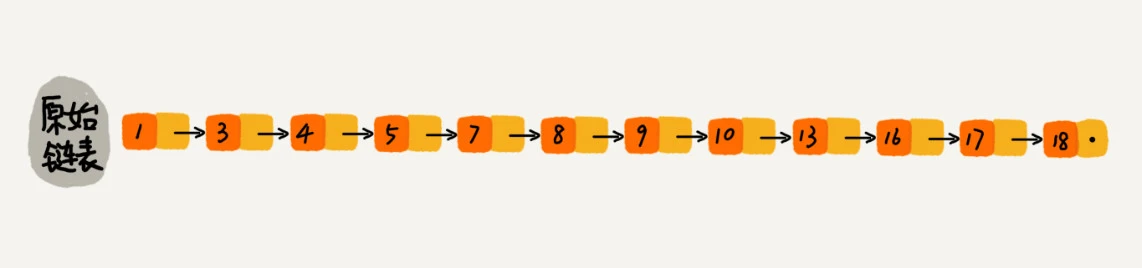
从链表中每两个结点提取一个结点到上一级,我们把抽出来的那一级叫做索引或索引层。如下图。图中的 down 表示 down 指针,指向下一级结点。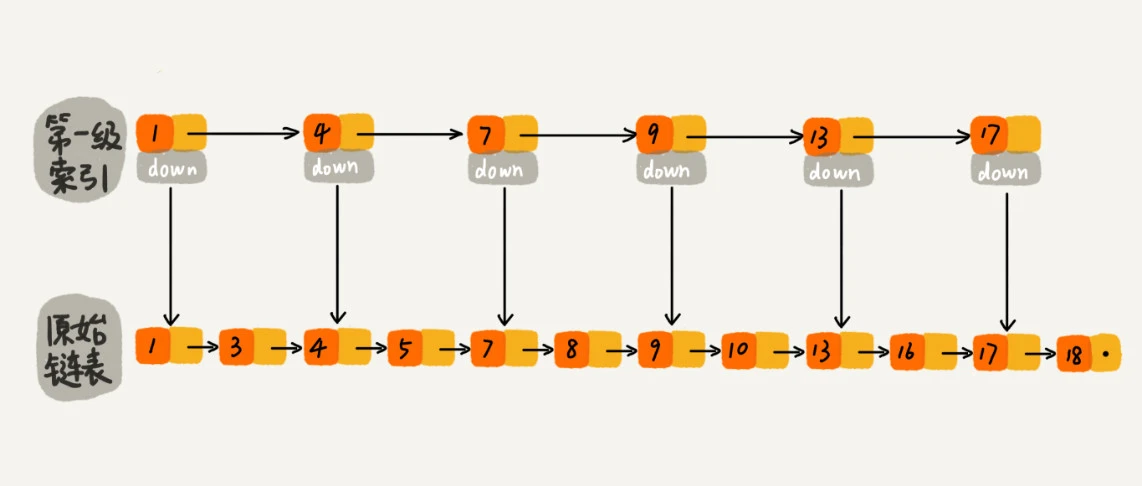
加来一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。
跟前面建立第一级索引的方式相似,我们在第一级索引的基础之上,每两个结点就抽出一个结点到第二级索引。查找一个结点需要遍历的结点数量又减少了。
这就是跳表的思想,用“空间换时间”,通过给链表建立索引,提高了查找的效率。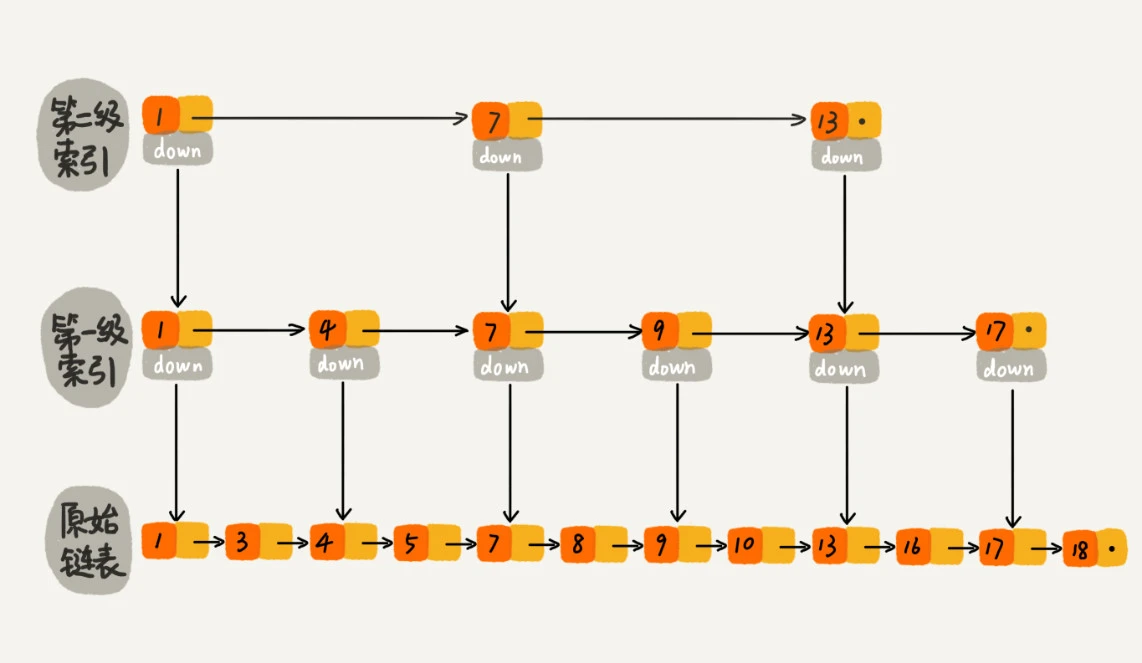
当元素数量较多时,建立多级索引,索引提高的效率比较大,近似于二分查找。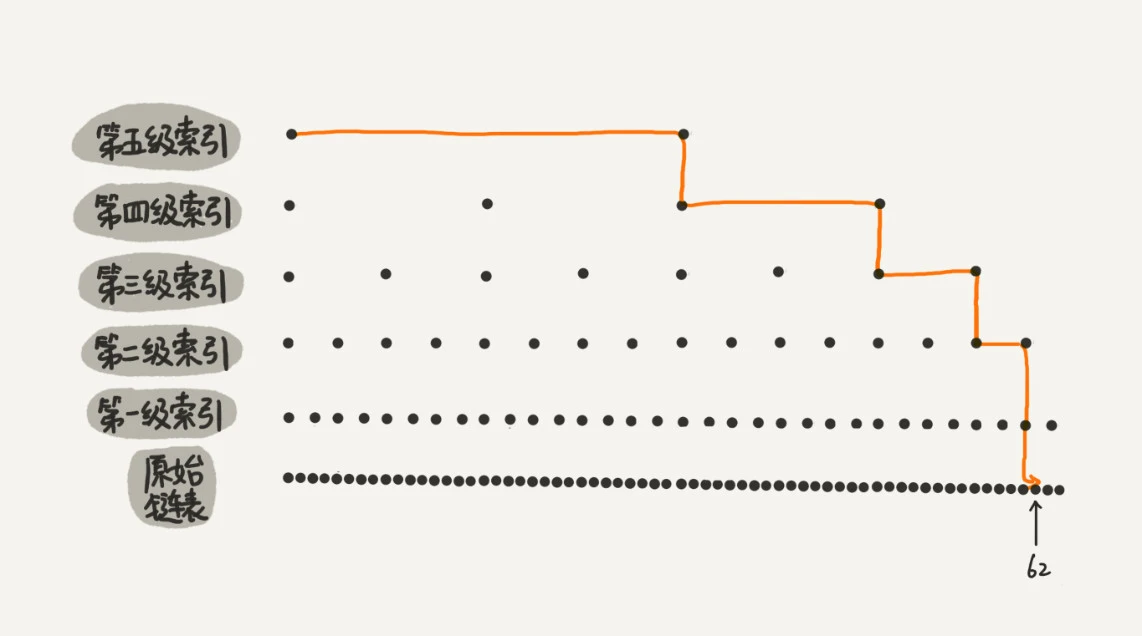
2. 跳表查找的时间复杂度
跳表查找元素的过程是从最高级索引开始,一层一层遍历最后下沉到原始链表。所以,时间复杂度 = 索引的高度 * 每层索引遍历元素的个数。
如果每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是n/2,第二级索引的结点个数大约就是n/4,第三级索引的结点个数大约就是n/8,依次类推,那第k级索引结点的个数就是n/(2^k)。
最高级索引一般有2个元素,即:最高级索引h满足2=n/(2^h),从而求得h=log2n-1,如果包含原始链表这一层,整个跳表的高度就是log2n。
按照前面这种索引结构,我们每一级索引都最多只需要遍历3个结点,根据时间复杂度 = 索引的高度 * 每层索引遍历元素的个数,即跳表中查找一个元素的时间复杂度为O(3*log2n),省略常数即:O(logn)。
3. 跳表的空间复杂度
跳表通过建立索引,来提高查找元素的效率,就是典型的“空间换时间”的思想,所以在空间上做了一些牺牲。
前面提到,如果每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是n/2,第二级索引的结点个数大约就是n/4,以此类推,每上升一级就减少一半,直到剩下2个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。
1 | n/2, n/4, n/8, ..., 8, 4, 2 |
这几级索引的结点总和就是n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是O(n)。也就是说,如果将包含n个结点的单链表构造成跳表,我们需要额外再用接近n个结点的存储空间。
我们前面都是每两个结点抽一个结点到上级索引,如果我们每三个结点或五个结点,抽一个结点到上级索引,第一级索引需要大约n/3个结点,第二级索引需要大约n/9个结点,以此类推,每往上一级,索引结点个数都除以3。通过等比数列求和公式,总的索引结点大约就是n/3+n/9+n/27+...+9+3+1=n/2。尽管空间复杂度还是O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
在软件工程中,对象数据所占的空间要远大于指针,指针大小可以忽略。
4. 跳表的插入和删除
跳表这个动态数据结构,插入、删除操作的时间复杂度也是O(logn)。
4.1 插入数据
跳表的插入首先查找某个数据应该插入的位置(时间复杂度是O(logn)),当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表。
需要某种手段来维护索引与原始链表大小之间的平衡。
当我们往跳表中插入数据的时候,我们可以选择同时将这个数据插入到部分索引层中。
我们通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第K级索引中。
随机函数简化跳跃链表建立层级索引的复杂度,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。
如下图所示,插入数据6到跳表中,随机函数生成K=2: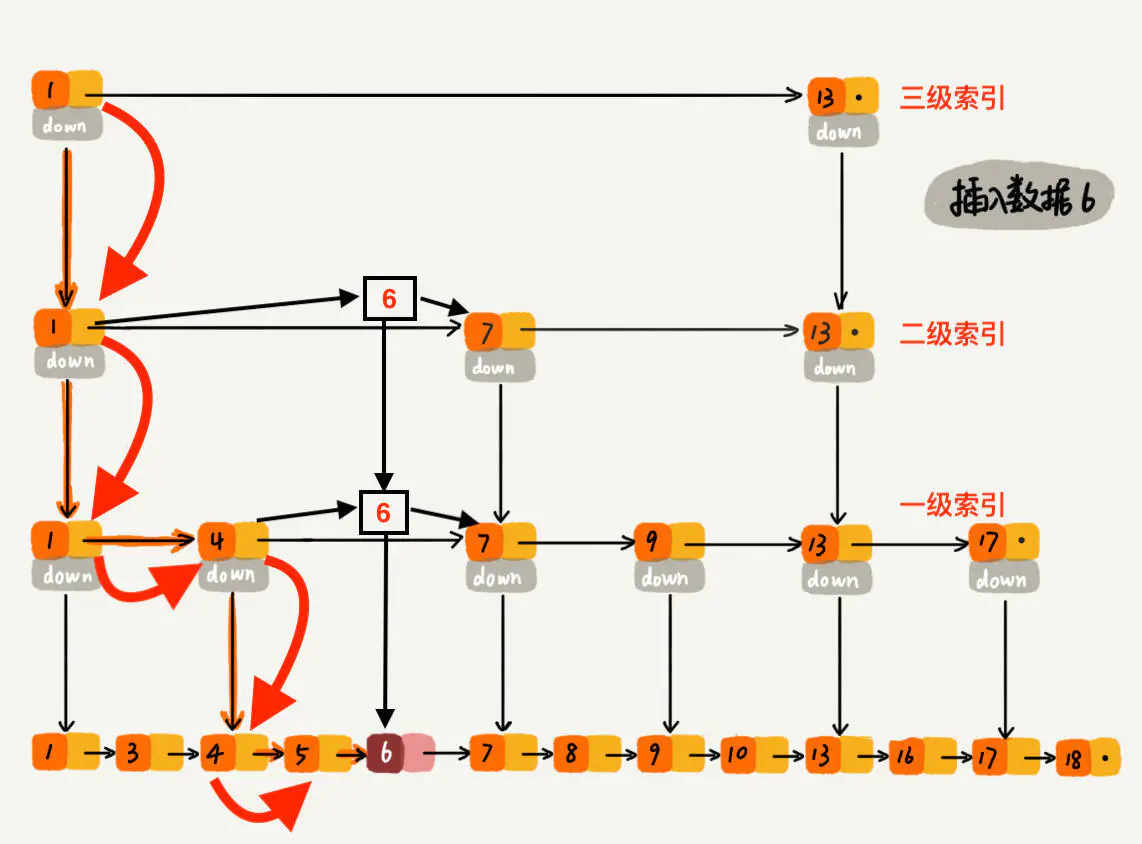
4.2 删除数据
跳表删除数据时,要把索引中对应节点也要删掉。
删除元素的过程跟查找元素的过程类似,只不过在查找的路径上如果发现了要删除的元素x,则执行删除操作。
如下图所示,如果要删除元素9,需要把原始链表中的9和第一级索引的9都删除掉。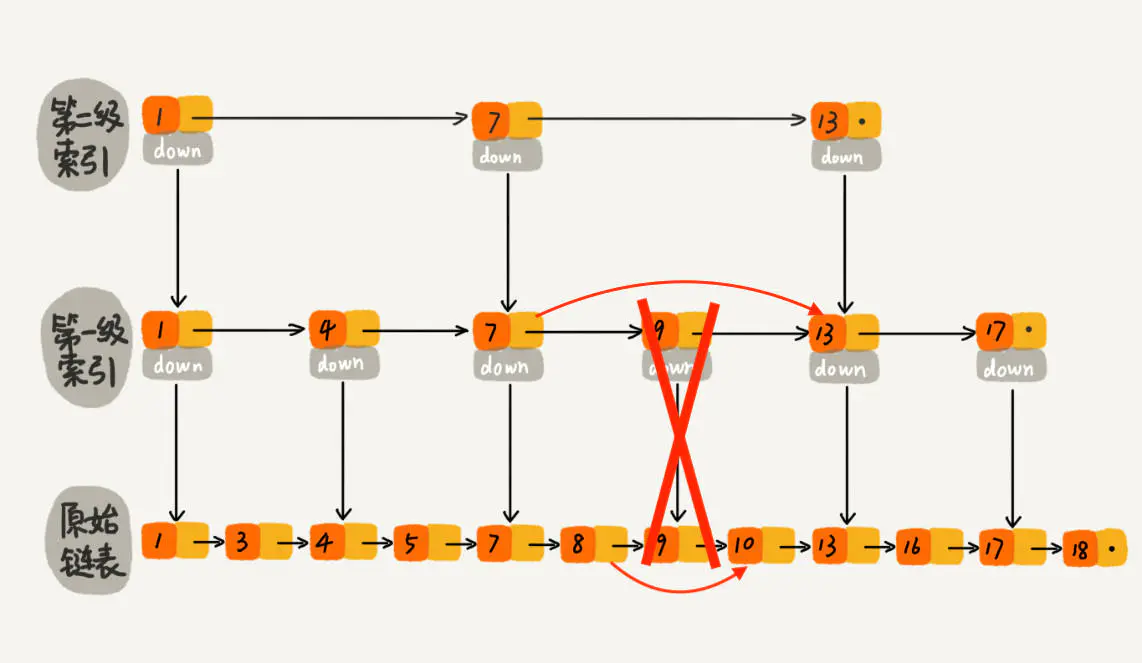
5. 总结
跳表是查询效率近似于二分查找的有序链表;
每个元素插入时随机生成它的索引层级level;
最底层原始链表包含所有的元素;
如果一个元素出现在x层索引,那么它肯定出现在x以下的索引层中;
跳表查询、插入、删除的时间复杂度为O(logn),与平衡二叉树接近;
原文链接: http://chaooo.github.io/2022/03/12/data-structure-skiplist.html
版权声明: 转载请注明出处.